Building maintainable cloud-native applications
Introduction Over the past years, I’ve had the chance to work with many clients on cloud-native applications, both new and legacy. From data pipelines to machine learning models to backend systems, I’ve seen it all—and along the way, I’ve witnessed p...

Introduction
Over the past years, I’ve had the chance to work with many clients on cloud-native applications, both new and legacy. From data pipelines to machine learning models to backend systems, I’ve seen it all—and along the way, I’ve witnessed plenty of failures. These experiences have taught me some lessons that I’m going to share in this blog.
Let’s start by painting a picture of the current state of affairs. In 2024, cloud-native application development is no longer novel. Many organizations are leveraging the cloud to build faster, scalable, and maintainable software. However, cloud platforms are complex. Developing for a specific cloud provider requires an in-depth understanding of that provider’s services, intricacies, and best practices. Initially, cloud engineers emerged as specialists to help engineering teams navigate this complexity. While this arrangement worked well for basic cloud adoption, it quickly became apparent that optimizing applications for cost-efficiency and scalability exposed a significant knowledge gap between cloud engineers and domain-specific engineers, such as data engineers. This gap often hinders teams from realizing the true benefits of the cloud—scalability and cost optimization.
In recent years, the industry has seen domain-specific engineers gaining cloud expertise. Now, many data engineers or backend engineers are capable of designing cloud architectures, writing infrastructure as code (IaC), and optimizing solutions for cloud-native applications. This should be a good thing, right? After all, the goal was to reduce reliance on separate cloud engineering teams and empower domain engineers with cloud knowledge. Unfortunately, despite this shift, many teams continue to struggle with building maintainable cloud-native applications that don’t become obsolete or unmanageable within a year.
When No One Wants to Touch the Code
What defines good software? Is it the software that helps users achieve their goals quickly? The one with the fewest bugs? Does it follow best practices like SOLID principles? While all these qualities contribute, I want to focus on maintainability.
Codebases are living entities. They require continuous updates, bug fixes, and new features. Moreover, they must adapt to changes in the underlying services, frameworks, and APIs that support them. Whether it’s to remain competitive or simply to keep up with the pace of innovation, a software system needs to be easy to maintain, or it will quickly fall into disrepair.
Every time I join a project, I need to spend time familiarizing myself with the codebase, running it in a safe environment to avoid breaking anything, and gradually experimenting until I have a good understanding of how it works. In my earlier days as an iOS developer, I worked on applications following well-established patterns like MVC, MVP, or MVVM. No matter how large or complex the project was, I always knew where to begin.
But as I transitioned to cloud-native development, I was struck by how drastically different every project could be. There were no consistent architectural patterns to rely on, making the learning curve for each new project steep and inefficient.
Maintaining software isn’t just about fixing bugs or adding features. It’s about how easily others can pick up where you left off. After leaving a team, you’ll be remembered by how maintainable your code is. New engineers will be able to ramp up more quickly, and teams will spend less time firefighting legacy code if your architecture is well-structured and maintainable from the start.
The Challenge of Separating IaC and Application Code
Even though we now have more domain-specific engineers proficient in cloud technologies, many teams still approach cloud-native development the same way they did years ago. A typical pattern is to maintain infrastructure as code (IaC) in a separate repository from the application code. This segregation reflects a belief that IaC and application code are separate concerns. But, in reality, they are deeply intertwined.
For example, take a project I worked on recently. We had application logic that dynamically determined the number of pipelines, which directly influenced the infrastructure (specifically, the creation of AWS Glue jobs). To handle this, we created static configuration files that fed into our Cloud Development Kit (CDK) scripts. However, this setup led to a convoluted codebase where infrastructure and application logic were tightly coupled but awkwardly communicated via configuration files.
Similarly, managing cloud resources like S3 buckets adds another layer of complexity. S3 bucket names must be globally unique, so for each environment, we needed different bucket names. The application logic needed access to these dynamically generated names, further blurring the line between application code and infrastructure.
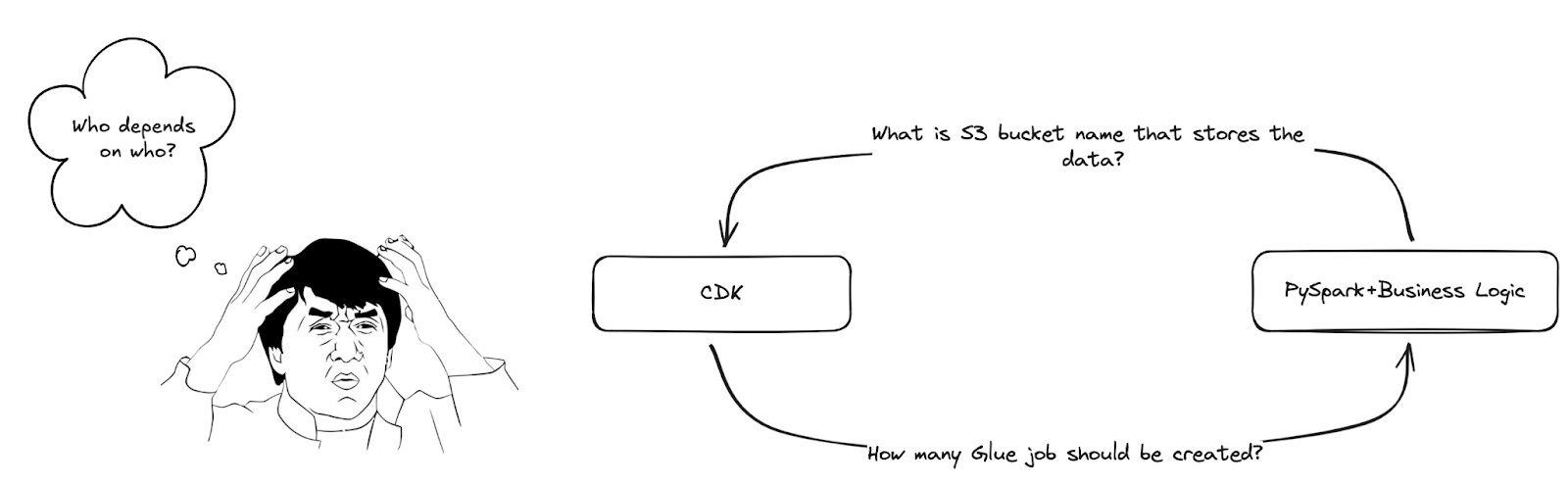
As these examples show, infrastructure and application logic are not truly independent. In most real-world cloud-native systems, there’s constant interaction between the two, and over time, the communication between these two codebases becomes more complex. To manage this, teams often resort to creative solutions: naming conventions, environment variables, shared databases, or parameter stores. However, these solutions are inherently brittle and don’t scale well as the system grows.
In that project, our configuration files quickly ballooned from a few parameters to an overwhelming set of variables. While it may have worked for those of us involved in the project from the start, anyone coming in later—like myself after a stint away—would have found it difficult to navigate. Worse, without proper safeguards, it’s easy for developers to misuse these workarounds, leading to even more complex and unmaintainable systems.
The Need for a Unified Approach
The current state of cloud-native development needs improvement. Unifying infrastructure and application code into a single codebase, or at least a more tightly integrated system, is not just a convenience—it’s essential for building scalable, maintainable cloud-native applications.
A unified approach removes the artificial barriers between infrastructure and application logic, allowing for seamless sharing of configurations, parameters, and modules. By adopting a unified codebase and treating IaC and application logic as two parts of the same whole, we can reduce complexity and ensure that our systems remain maintainable as they scale.
In this post, I covered the current state of cloud-native development, the challenges of maintaining scalable applications, and the complexities of separating infrastructure from application code. In future posts, I’ll dive deeper into how we can address these challenges with modern architectural patterns and introduce a framework designed to bridge the gap between infrastructure and application code, simplifying cloud-native development for teams of all sizes.