



What is AWS CDK
AWS CDK is a software development framework for defining cloud infrastructure in code and provisioning it through AWS CloudFormation. So before explaining more about CDK, let’s first elaborate more about Infrastructure as Code and CloudFormation.
“Infrastructure as Code is an approach to infrastructure automation based on practices from software development. It emphasizes consistent, repeatable routines for provisioning and changing systems and their configuration. You make changes to code, then use automation to test and apply those changes to your systems.” Excerpt From: Kief Morris. “Infrastructure as Code, 2nd Edition”.
“AWS CloudFormation is a service that helps you model and set up your Amazon Web Services resources so that you can spend less time managing those resources and more time focusing on your applications that run in AWS. You create a template that describes all the AWS resources that you want (like Amazon EC2 instances or Amazon RDS DB instances), and AWS CloudFormation takes care of provisioning and configuring those resources for you. It helps you to provision and create your AWS infrastructure easily and repeatedly.”
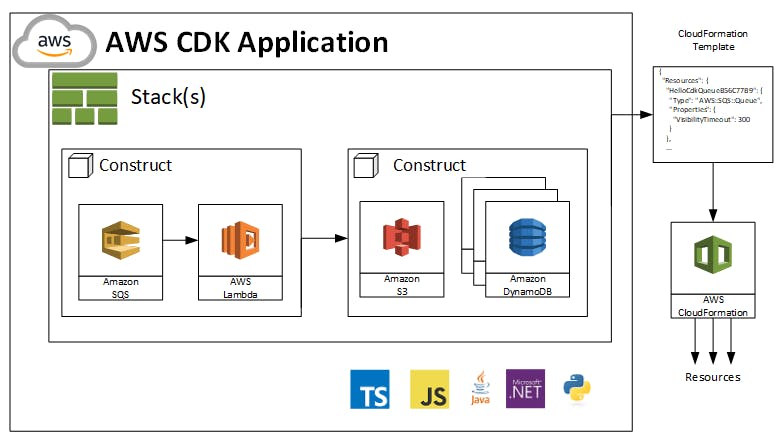
CDK acts like a wrapper around CloudFormation. It lets you prepare, create, and provision your AWS resources in your preferred language. It is originally created by Typescript and already supports Javascript, python, java, and C#/.Net.
Main components of CDK are as follows:
App: is the core or your CDK application. It acts like a container which consists of one or multiple stacks.
Stack(equivalent to AWS CloudFormation stacks): is the unit of deployment in CDK. Each individual stack would be translated into one AWS CloudFormation template.
Construct: represents a “cloud component” and encapsulates everything AWS CloudFormation needs to create the component. They (as well as stacks and apps) are represented as types in your programming language of choice. You instantiate constructs within a stack to declare them to AWS, and connect them to each other using well-defined interfaces.
Developers use one of the mentioned supported programming languages to define reusable cloud components (Constructs) and compose them into Stacks and Apps.
In this article, we are going to use CDK to deploy a simple Glue job. We assume that you already have CDK installed on your system. If not, you can install CDK by following this link. Make sure you do not forget to get the prerequisites prepared beforhand.
Initialize the CDK project
In terminal:
$ mkdir cdk-glue-job
$ cd cdk-glue-job
$ cdk init app --language=typescript
The cdk init command creates a number of files and folders inside the cdk-glue-job directory to help you organize the source code for your AWS CDK app.
In the “cdk-glue-job.ts” you will find the app codes which will initialize the stack that we want to create. The code for our stack will be residing in “lib/cdk-glue-job-stack.ts”. Also you can find the dependencies of the project in “package.json”.
Let’s start completing “lib/cdk-glue-job-stack.ts” little by little.
Define an IAM Role
First, we define a role to be assumed by our glue job. To do so, we need to add the “@aws-cdk/aws-iam” package to the project. To do so, we run "$ npm install @aws-cdk/aws-iam" in the command line. After running the command, it will be automatically added to package.json dependencies.
Then we add the following code to “lib/cdk-glue-job-stack.ts”:
const role = new iam.Role(this, 'my-glue-job-role', {
assumedBy: new iam.ServicePrincipal('glue.amazonaws.com'),
});
const gluePolicy = iam.ManagedPolicy.fromAwsManagedPolicyName("service-role/AWSGlueServiceRole");
role.addManagedPolicy(gluePolicy);
Define S3 bucket
For the next step, we want to add an s3 bucket to our stack. To do so, we add the “@aws-cdk/aws-s3” package to the project by running "$ npm install @aws-cdk/aws-s3" in the command line.
Then we need to add the following code to “lib/cdk-glue-job-stack.ts”:
const myBucket = new s3.Bucket(this, 'MyCdkGlueJobBucket', {
versioned: true,
bucketName: '<id>-my-cdk-glue-job-bucket',
removalPolicy: cdk.RemovalPolicy.RETAIN,
blockPublicAccess: s3.BlockPublicAccess.BLOCK_ALL
});
myBucket.grantRead(role);
s3.Bucket() will create a bucket with provided properties. As you can see, we’ve just set 4 properties at the moment, but you can visit here to see all the properties that can be provided when configuring an S3 bucket.
For the bucket name, we must provide a unique name in S3. For this reason, you should include your AWS account id in the bucket name or just provide a unique name. The removal policy “cdk.RemovalPolicy.RETAIN”, will ensure that this Bucket will not be deleted when we delete our CloudFormation stack.
Define Glue Job
Add “@aws-cdk/aws-glue” to the project by running “npm install @aws-cdk/aws-glue” in the terminal.
And here is the code with a minimal set of properties that we use to define the glue job:
new glue.CfnJob(this, 'my-glue-job', {
role: role.roleArn,
command: {
name: 'pythonshell',
pythonVersion: '3',
scriptLocation: 's3://<id>-my-cdk-glue-job-bucket/glue-python-scripts/hi.py'
}
});
Where is to be substituted with your aws account id. All the properties that you can provide are mentioned here.
Most of the CDK modules are created based on CloudFormation modules, It is also handy to check CloudFormation Documents as well!
For the name of the job, there are some rules that must be followed! For the python shell jobs, you must provide exactly “pythonshell” and for Apache spark ETL jobs, you must exactly provide “glueetl”. It will not work if you provide something else!
The “scriptLocation” property shows the path in S3 bucket that we want to provide the python script afterwards.
Provide a python script code
In our project, create a directory named “resources” and inside that, create another one, named “glue-scripts”. And finally create a python file, named “hi.py” with the following simple hello world!
print(‘Hello from python-shell glue job, created by CDK!’)
Now we need to provide some code to move this file into the S3. To do so, we use s3 deployment. So first we add it to the project by running “npm install @aws-cdk/aws-s3-deployment” and then add the following code to “lib/cdk-glue-job-stack.ts”:
new s3deploy.BucketDeployment(this, 'DeployGlueJobFiles', {
sources: [s3deploy.Source.asset('./resources/glue-scripts')],
destinationBucket: myBucket,
destinationKeyPrefix: 'glue-python-scripts'
});
We provided the source and destination to BucketDeployment module. Just the last step to make the magic happen is bootstrapping.
$ cdk bootstrap aws://ACCOUNT-NUMBER-1/REGION-1
and it is done! we are now ready to deploy our stack.
Deploy to AWS
By just running
$ cdk deploy
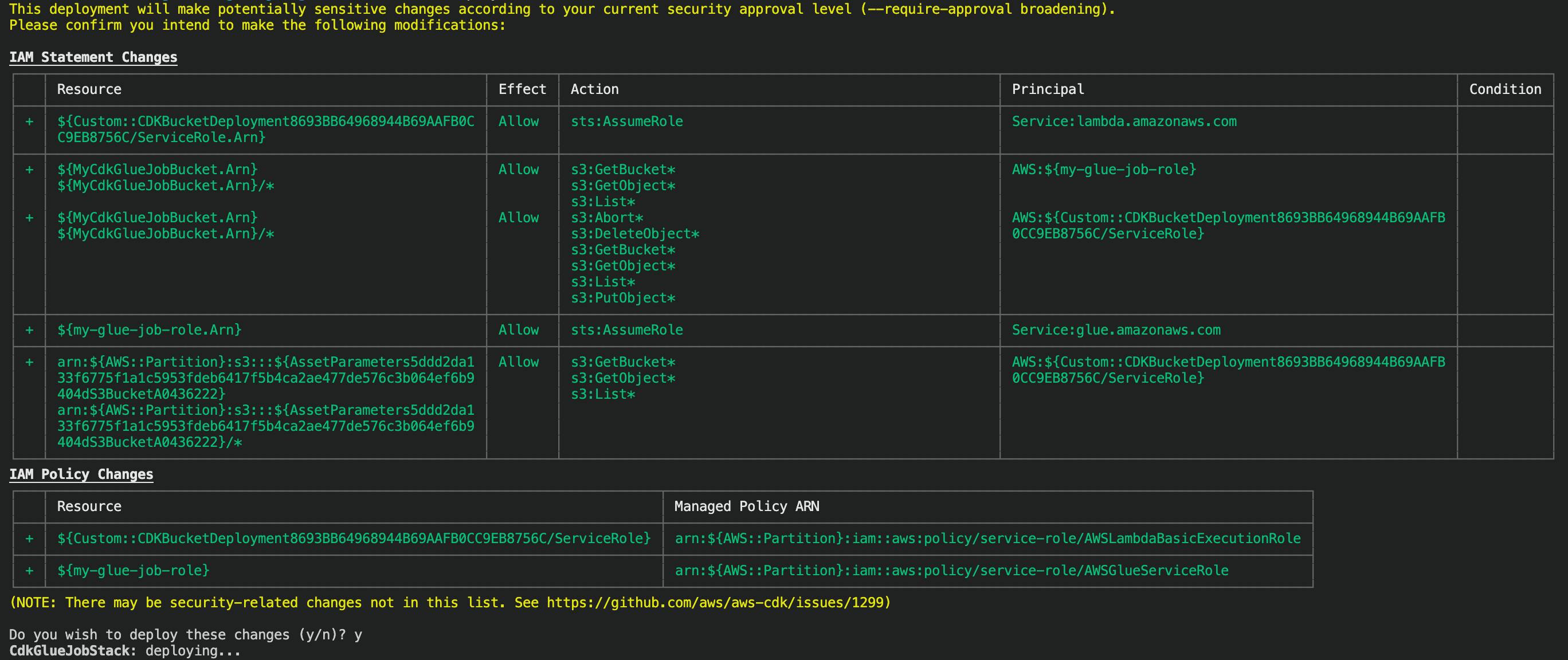
We can easily deploy our project to AWS. It will first create a CloudFormation template from our CDK codes, and then try to deploy it to the cloud. After running “cdk deploy”, you will be prompted by the changes that CDK want to do
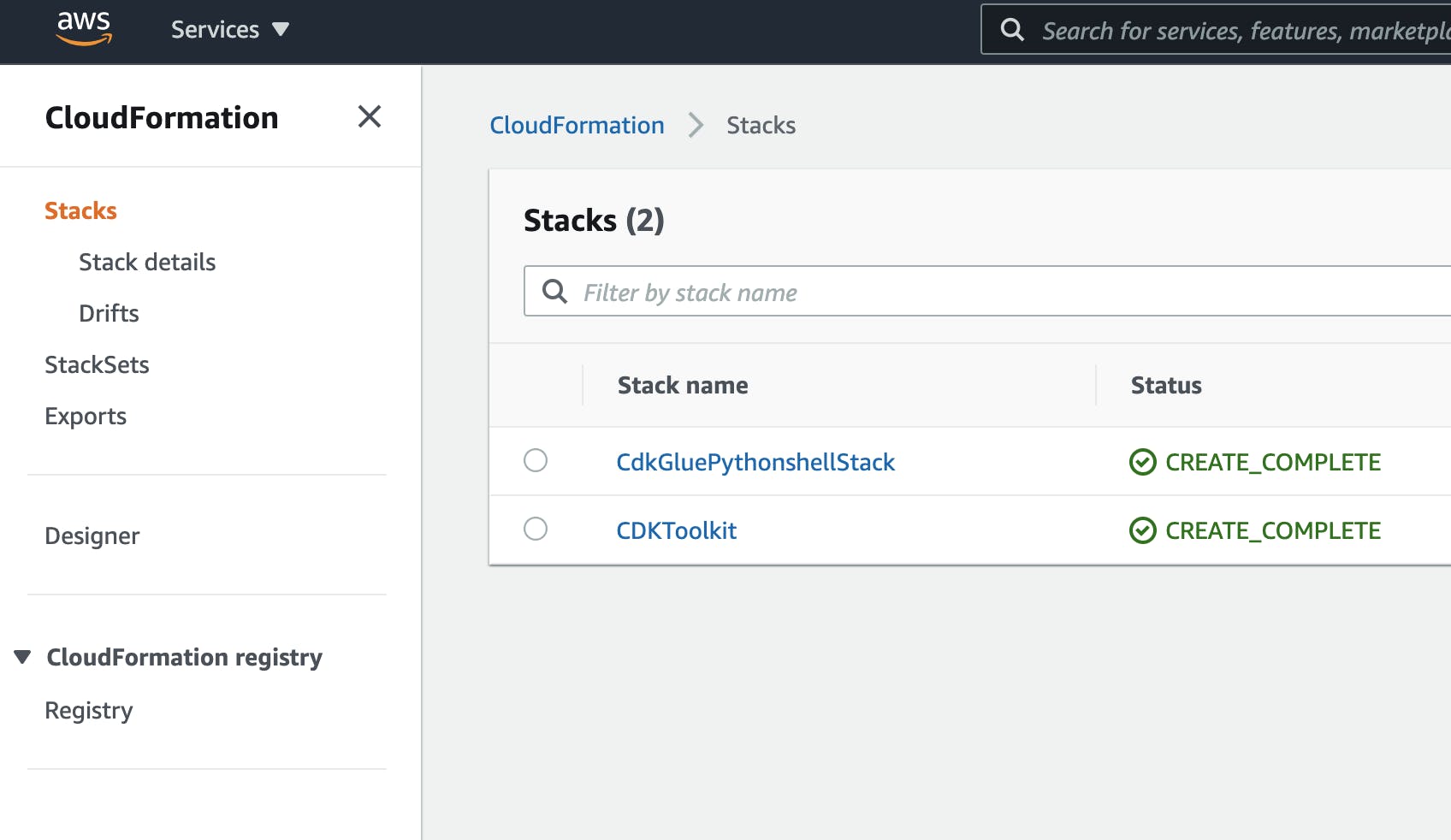
After the successful deployment, you can check the stack in your AWS console, in your CloudFormation stacks.
In S3, You will find your bucket and hi.py inside it. And in your Glue service, in the job menu, you will find a new python-shell job.
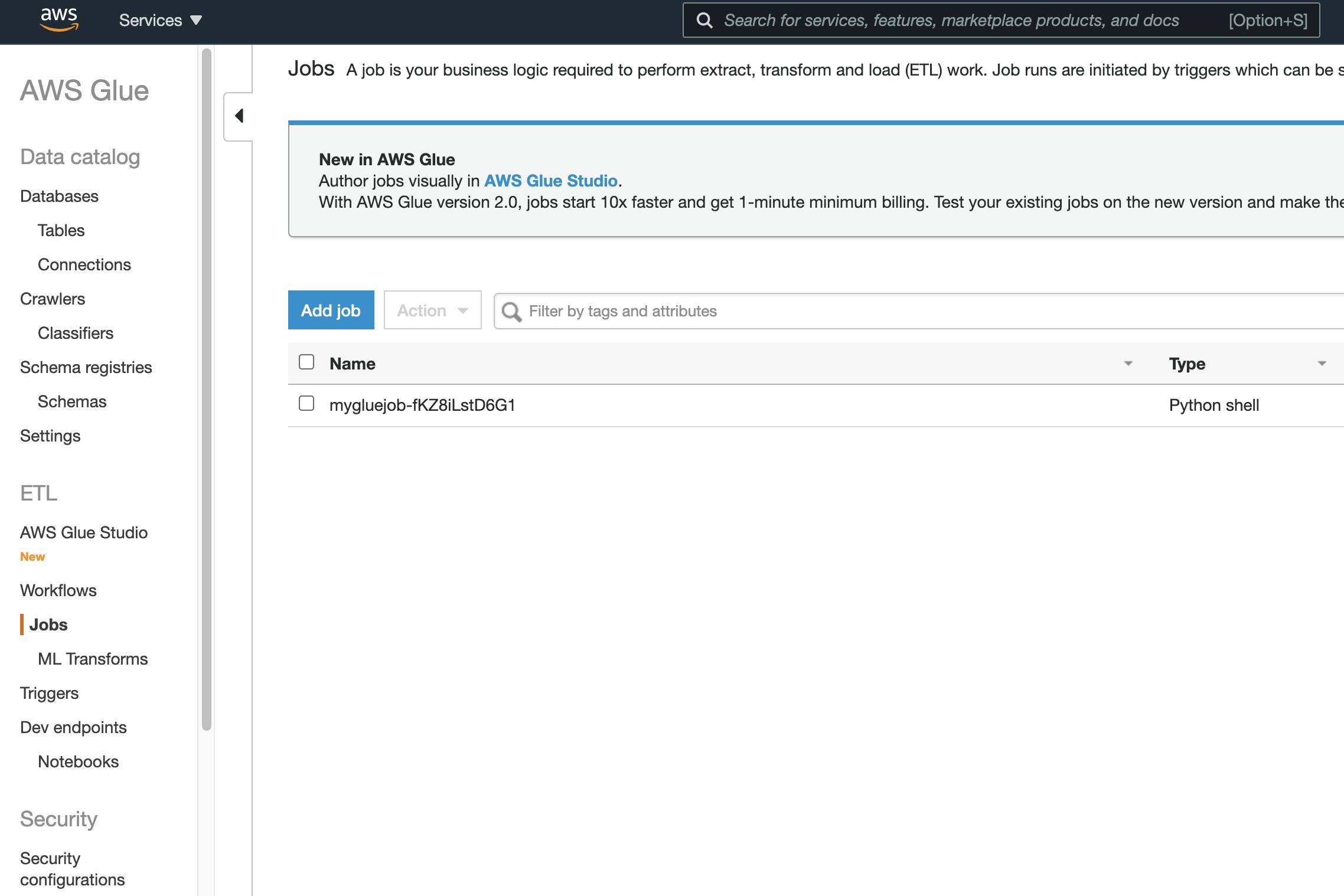
Delete the stack from AWS
For this reason, just run “cdk destroy”. Everything will be deleted from AWS except the bucket we created! because we provide “removalPolicy: cdk.RemovalPolicy.RETAIN”, remember?
$ cdk destroy
So if you want to run “cdk deploy” after deleting the stack, you first need to remove that bucket manually, or just change the policy to “cdk.RemovalPolicy.DESTROY”.