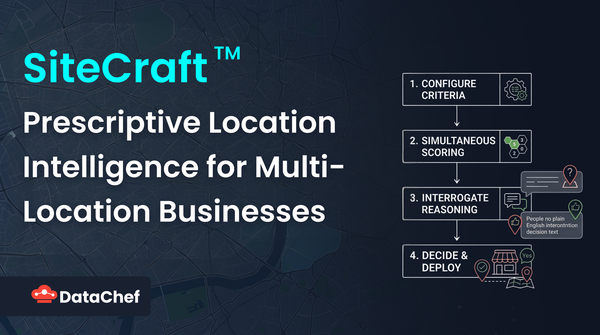
Deserialzing Confluent Avro Records in Kafka with Spark
Introduction Kafka producers and consumers are already decoupled in the sense that they do not communicate with one another directly; instead, information transfer happens via Kafka topics. But they are coupled in the sense that consumers need to kno...

Introduction
Kafka producers and consumers are already decoupled in the sense that they do not communicate with one another directly; instead, information transfer happens via Kafka topics. But they are coupled in the sense that consumers need to know what the data they are reading represents in order to make sense of it—but this is something that is controlled by the producer! How can producers evolve the schema of data without breaking downstream services?
To facilitate this, Confluent introduced Schema Registry for storing and retrieving Avro, Json schema and Protobuf schemas and they decided Avro as default choice. If you have a Kafka cluster populated with Avro records governed by Confluent Schema Registry, you can’t simply add spark-avro dependency to your classpath and use from_avro function. Why? That’s because in order to work in close integration with the Kafka consumer or producer, the Confluent team has manipulated the binary format. If you know already how Avro works, you can skip the introduction and go straight to Confluent Avro format.
Avro crash course!
Apache Avro is a language-neutral data serialization system. The project was created by Doug Cutting, the creator of Hadoop, to address the major downside of Hadoop Writables: lack of language portability. Having a data format that can be processed by many languages makes it easier to share datasets with a wider audience than one tied to a single language. It is also more future-proof, allowing data to potentially outlive the language used to read and write it.
But why a new data serialization system? Avro has a set of features that, taken together, differentiate it from other systems such as Apache Thrift or Google’s Protocol Buffers. However, unlike in some other systems, code generation is optional in Avro, which means you can read and write data that conforms to a given schema even if your code has not seen that particular schema before. To achieve this, Avro assumes that the schema is always present — at both read and write time — which makes for a very compact encoding, since encoded values do not need to be tagged with a field identifier.
Avro Schema
Avro schemas can be written in two ways, either in a JSON format:
{
"type": "record",
"name": "Person",
"fields": [
{
"name": "userName",
"type": "string"
},
{
"name": "favouriteNumber",
"type": [
"null",
"long"
]
},
{
"name": "interests",
"type": {
"type": "array",
"items": "string"
}
}
]
}
Or using a higher-level language called Avro IDL:
record Person {
string userName;
union { null, long } favouriteNumber;
array<string> interests;
}
Serialization and deserialization
There are two ways to achieve this, either using Generic API or using Specific API. Specific API is used in conjunction with automatic code generation from Schema.
Generic API
Here is the serialization part:
val schemaDefinition =
"""
|{
| "type": "record",
| "name": "Customer",
| "doc": "Information about a customer",
| "fields": [
| {"name": "id", "type": "string"},
| {"name": "name", "type": "string"}
| ]
|}
|""".stripMargin
val parser = new Schema.Parser()
val schema = parser.parse(schemaDefinition)
val record = new GenericData.Record(schema)
record.put("id", "44L")
record.put("nam", "John")
val outputStream = new ByteArrayOutputStream()
val datumWriter = new GenericDatumWriter[GenericRecord](schema)
val encoder = EncoderFactory.get().binaryEncoder(outputStream, null)
datumWriter.write(record, encoder)
encoder.flush()
outputStream.close()
// Get byte array encoded with Avro format
val result = outputStream.toByteArray
We can reverse the process and read the object back from the byte buffer:
val decoder = DecoderFactory.get().binaryDecoder(outputStream.toByteArray, null)
val datumReader = new GenericDatumReader[GenericRecord](schema)
val record2 = datumReader.read(null, decoder)
println(record2.get("id")) // 44L
println(record2.get("name")) // John
Specific API
The Generic way works well for small schemas and small applications, but as your schema grows, it will become unmanageable. If you have typo in field names, you won’t notice until runtime with AvroRuntimeException and also dealing with Object type and managing type conversion manually is very cumbersome. That’s where Specific API comes handy. Thanks to code generation functionality, your time will be saved, and you have more manageable and cleaner code.
Add sbt-avro plugin to your project, then put your schema in src/main/avro/ folder and then type: sbt avroGenerate
It generates the classes, in our case Customer class, then we can use specific API like this:
val customer = new Customer()
customer.setId("87R")
customer.setName("Alice")
// Serialization
val out = new ByteArrayOutputStream()
val writer = new SpecificDatumWriter[Customer](classOf[Customer])
val encoder = EncoderFactory.get.binaryEncoder(out, null)
writer.write(customer, encoder)
encoder.flush()
out.close
// Deserialization
val reader = new SpecificDatumReader[Customer](oldSchema, newSchema)
val decoder = DecoderFactory.get.binaryDecoder(out.toByteArray, null)
val result = reader.read(null, decoder)
println(result.getId) // 87R
println(result.getName) // Alice
Schema Evolution
Changes are inevitable in the software industry, and sooner or later the requirements will change, and as a software developer, you should change the schema. But before changing the schema you should think about downstream services and ask questions like this: Who do we upgrade first? consumers or producers? Can new consumers handle the old events that are still stored in Kafka? Do we need to wait before we upgrade consumers? Can old consumers handle events written by new producers?
This can get a bit complicated, so data formats like Avro and Protobuf define the compatibility rules concerning which changes you’re allowed to make to the schema without breaking the consumers, and how to handle upgrades for the different types of schema changes. In other words, the schema that the producer writes is not always the schema that the consumer reads.
That’s why both Generic and Specific API have constructors for specifying writer and reader schema:
val reader = new SpecificDatumReader[Customer](writerSchema, readerSchema)
The table below, summarize the rules for record evolution from the point of view of readers and writers:
| Writer's schema | Reader's schema | Action | Behaviour |
| Old | New | New field has been added to the Reader’s schema | The reader uses the default value of the new field, since it is not written by the writer. |
| New | Old | New field has been added to the Writer's schema | The reader does not know about the new field written by the writer, so it is ignored. |
| Old | New | Field has been removed from the Reader’s schema | The reader ignores the removed field. |
| New | Old | Field has been removed from the Writer’s schema | The removed field is not written by the writer. If the old schema had a default defined for the field, the reader uses this; otherwise, it gets an error. In this case, it is best to update the reader’s schema, either at the same time as or before the writer’s. |
For a more detailed information check Schema Resolution in Avro’s documentation.
Revealing the confidential Confluent Avro Format!
In order to producers and consumers seamlessly work together, Confluent team has appended the Schema id before actual standard Avro binary format. In this way, consumers can fetch the Schema id, request the schema from Schema Registry and deserialize the bytes. The Confluent Avro format looks like this:

Confluent Avro Format
SerDes in Spark
Because the binary format is not the standard Avro format but Confluent format, we cannot simply add spark-avro dependency and use from_avro function. But because the Confluent Avro format is super simple, we can extract the schema id and deserialize the Avro binary using Avro api. For instance, this method, get Confluent Avro binary, and deserialize the Avro:
def deserializeFromConfluentAvro(bytes: Array[Byte]): Account = {
val schemaRegistryUrl = "http://schema-registry-url:8081"
val schemaRegistry = new CachedSchemaRegistryClient(schemaRegistryUrl, 128)
val buffer = ByteBuffer.wrap(bytes)
// The first byte is magic byte
if (buffer.get != 0) throw new SerializationException("Unknown magic byte!. Expected 0 for Confluent bytes")
// The next 2 bytes are schema id
val writeSchemaId = buffer.getInt()
val writerSchema = schemaRegistry.getByID(writeSchemaId)
// we want to deserialize with the last schema
val subject = "your-topic-name" + "-value"
val readerSchemaId = schemaRegistry.getLatestSchemaMetadata(subject).getId
val readerSchema = schemaRegistry.getByID(readerSchemaId)
val length = buffer.limit - 1 - 4
val start = buffer.position() + buffer.arrayOffset()
val decoder = DecoderFactory.get().binaryDecoder(buffer.array(), start, length, null)
val reader = new SpecificDatumReader[Account](writerSchema, readerSchema)
reader.read(null, decoder)
}
And in order to extract value from Spark’s Dataframe, you need to write a user defined function:
val deserializeAvro: UserDefinedFunction = udf(
(bytes: Array[Byte]) => {
deserializeFromConfluentAvro(bytes)
}
)
Then use it like this:
df.select(deserializeAvro(col("value")))
But when you run it, you will get the error: java.lang.UnsupportedOperationException: Schema for type Customer is not supported. My next move was to use Dataframe’s mapPartitions method. Here is the method’s signature:
def mapPartitions[U : Encoder](func: Iterator[T] => Iterator[U]): Dataset[U]
But as you can see, it requires that the return type has a Encoder. So I added the encoder:
implicit val encoder = Encoders.bean(classOf[Customer])
But this also not worked, I got this error: Error: Cannot have circular references in bean class. Customer class is generated class, so I have no way to modify it.
ABRiS project to the rescue
from_avro function has some limitations, it only accepts the writer’s schema. That means it should deserialize with the exact schema that has been written. There is a pull request to address it but it will be available in Spark 3.0.
Manually deserializing Confluent format is easy but figuring out the right encoder for Spark is tricky. Thanks to the contributors of ABRiS project, they addressed all the issues in their project and now we are using it in our production. Here is the sample code to deserialize records:
var rawKafka = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", config.bootstrapServers)
.option("subscribe", config.topic)
.option("startingOffsets", config.startingOffsets)
.load()
val commonRegistryConfig = Map(
SchemaManager.PARAM_SCHEMA_REGISTRY_URL -> config.schemaRegUrl,
SchemaManager.PARAM_SCHEMA_REGISTRY_TOPIC -> config.topic,
"basic.auth.credentials.source" -> "USER_INFO",
"schema.registry.basic.auth.user.info" -> s"${apiKey}:${apiPass}")
val keyRegistryConfig = commonRegistryConfig ++ Map(
SchemaManager.PARAM_KEY_SCHEMA_NAMING_STRATEGY -> "topic.name",
SchemaManager.PARAM_KEY_SCHEMA_NAMESPACE_FOR_RECORD_STRATEGY -> "key",
SchemaManager.PARAM_KEY_SCHEMA_ID -> "latest")
val valueRegistryConfig = commonRegistryConfig ++ Map(
SchemaManager.PARAM_VALUE_SCHEMA_NAMING_STRATEGY -> "topic.name",
SchemaManager.PARAM_VALUE_SCHEMA_NAMESPACE_FOR_RECORD_STRATEGY -> "value",
SchemaManager.PARAM_VALUE_SCHEMA_ID -> "latest")
rawKafka.select(
from_confluent_avro(col("key"), keyRegistryConfig).alias("key"),
from_confluent_avro(col("value"), valueRegistryConfig).alias("value"))
Of course you should change the configuration values according to your need. Also pay attention to schema registry authentication method, we used basic authentication method:
"basic.auth.credentials.source" -> "USER_INFO",
"schema.registry.basic.auth.user.info" -> s"${apiKey}:${apiPass}"
If you have configured your schema registry to use other authentication methods,you should change these accordingly.