




Context
A few weeks ago we were contacted by FrieslandCampina to help them with a problem they faced on their recommendation engine. Being one of the biggest dairy companies in the world they sell hundreds of dairy products to millions of customers across the globe. To help with their sales team, they developed a recommendation system that suggests the next items for each customer based on their purchase history. At the heart of this system lies the FP-Growth algorithm and this algorithm failed to run successfully for some subset of their customers. This issue interrupted the project since it forced the user to manually intervene and skip these “problematic” subsets. Here we discuss this algorithm in depth and along the way find out what went wrong with those mysterious “problematic” subsets.
FP-Growth Algorithm
The FP-Growth Algorithm, short for Frequent Pattern Growth, facilitates the construction of an FP-tree, which captures the frequency of item occurrences and their interrelations. Through a recursive procedure, the tree is efficiently mined to identify the most common itemsets, enabling the recommendation of new items based on these established itemsets.
Let's clarify these concepts further and delve deeper into the mechanics of the algorithm.
Itemsets
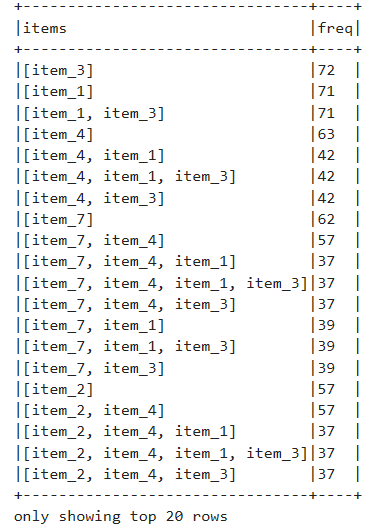
Itemsets are sets of items bought together in a transaction. This is our starting point!
Support and Min_Support
Support is an important metric in the FP-Growth algorithm. It is defined as the percentage of all transactions that include a pattern. For example, based on the below table, the Support([item_3]) is 72% since it could be found in 72% of all transactions. Min_Support is the most important parameter of this model which determines the cutoff value for a pattern to be considered, so if the Min_Support is set to 0.5 all patterns that are in less than half of the transactions will be ignored. This will have important consequences which we will discuss later!
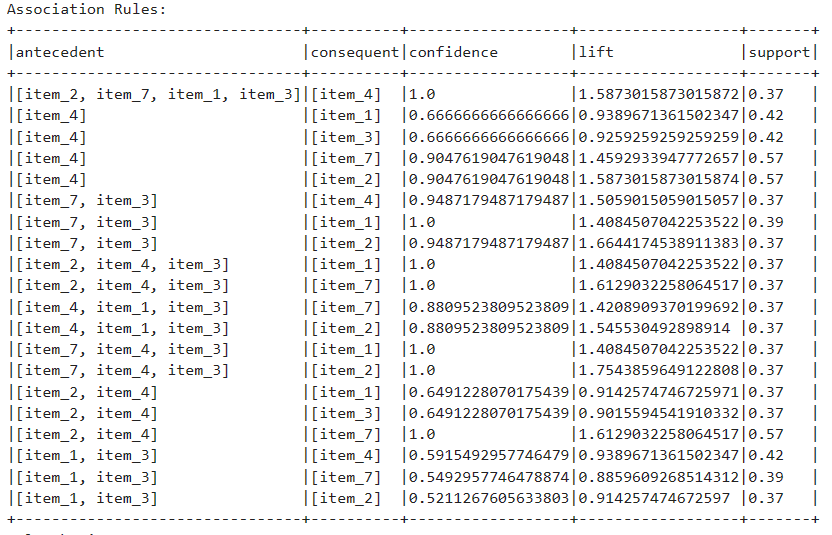
Association Rules
Association Rules are what our model learned from the data. It has an antecedent which means the items already in the itemset, and a consequent which is the recommendation based on the current itemset, this rule has confidence which shows how certain our model is about this rule. In practice, a cut-off of 0.5-0.8 can be applied to the confidence.
Final Result (Predictions)
Finally, we want a prediction column containing the recommendations we found for each customer based on their current itemset. Note that some of the customers may not get any recommendations this can be tuned by the Min_Support and Min_Confidence parameters.


Where is the Dark Side?
FP-Growth was first designed by J Han et al 2000 as a faster alternative to classical methods like the Apriori algorithm. Later a parallelized version of this algorithm was proposed (H Li et al 2008), which we are using through pyspark.ml library. This implementation harnesses the power of multiple CPU cores you have to speed up the process.
As the graph below shows, the pyspark implementation of FP-Growth can run on millions of itemsets (here they have about 10 items each) in practical time.
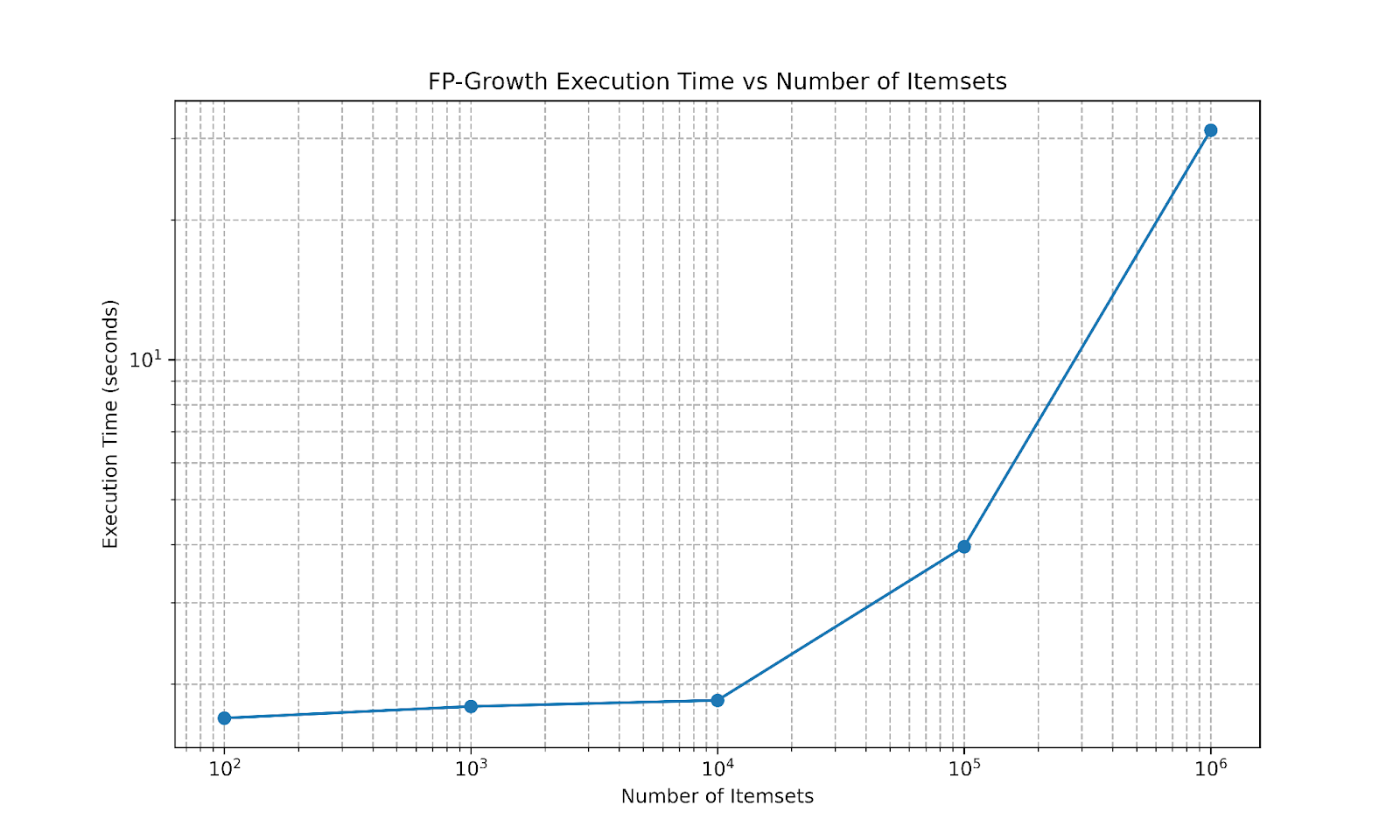
So where is this Dark Side we need to avoid? In this kind of problem, we usually look for dataset size as the measure of the scale of the problem but this can be misleading since there is another very important metric here: the size of each itemset.
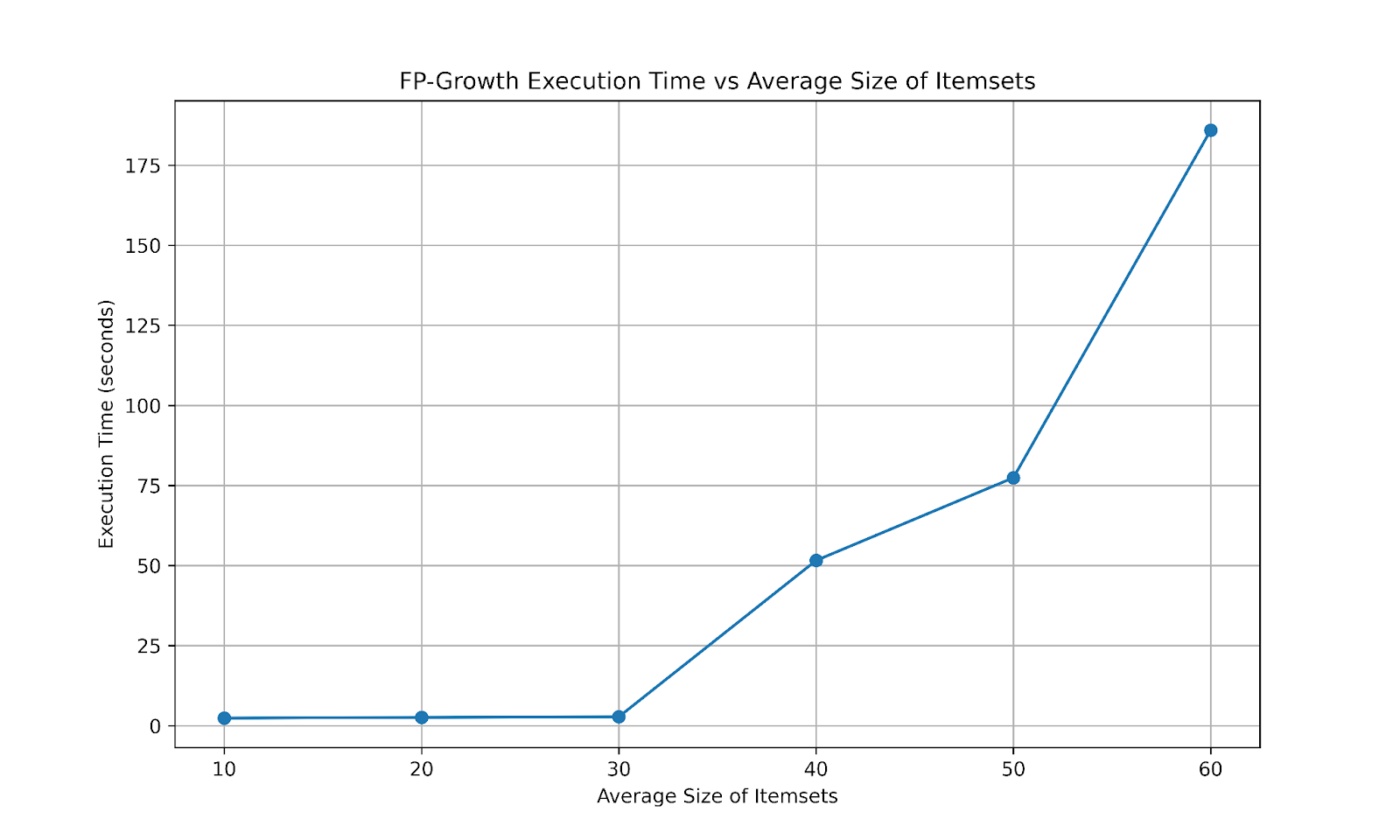
The chart above shows how important the size of itemsets is. It was impossible to run it on my laptop after an average size of 60! This can be traced back to the algorithm where it creates FP-Tree and searches them for patterns recursively. This step can grow exponentially when the size of the itemset is increased. This was exactly what went wrong with those "problematic" subsets in FrieslandCampina! The problematic ones had signficantly higher median size of itemsets that led to infinite computaion/memory needs.
How to solve it?
Solving this problem can mean different things based on the business requirements and development capacities you have!
A simple yet effective solution would be to adjust the Min_Support parameter based on the size of the itemsets and increase it accordingly (from 0.2 to 0.8). This way you are applying a powerful cut-off that first filters out some of the items that don’t have enough support and later decreases the number of association rules resulting in faster applications of them on the dataset. There is an edge case where all of the customers bought almost all of the available items where this fails but in that case, there is not so much to gain from recommendation anyway!
Another solution which is more robust but is more complicated and developer-consuming is to break each itemset into smaller manageable sub-itemsets and treat them as separate transactions. This splitting can be done in many overlapping or non-overlapping ways (which can be a source of confusion!). This way you decrease the complexity of the problem with the cost of losing some of the information.
Conclusion
Here we learned about the FP-Growth algorithm and how it can help the sales team with new product recommendations. We discussed this algorithm in depth and showed one of its caveats that if ignored can cause computation problems. We finally proposed some solutions for that problem.