How to choose the best training instance on SageMaker

DataChef, founded in 2019, is a boutique consultancy specializing in AI and data management. With a diverse team of 20, we focus on developing Data Mesh, Data Lake, and predictive analytics solutions via AWS, improving operational efficiency, and creating industry-specific machine learning applications.
Like EC2 instances, Amazon offers a variety of instances for training in SageMaker. Based on CPU cores, memory size and presence of GPUs, they come with different on-demand prices. A complete list can be found at Amazon SageMaker Pricing Page. From my point of view, too many choices is as bad as having none or limited choices, when you don’t have a clear idea how to choose. How do you handle the overwhelm of choosing an appropriate instance type for your training task on SageMaker? Do you just randomly pick one and hope that it’s good enough? The problem is, by choosing an inappropriate instance you may be over-provisioning which incurs higher prices, or under-provisioning which results in longer training time. Now how to save money and accomplish the task faster? Read on.
Instance Families
If you already know about instance families and you are here for the practical steps to choose the best instance, you can skip all the way to the [“How to choose the best instance”](#how-to-choose-the-best-instance "How to choose the best instance") section. But first, let us have a quick look into different families of SageMaker instances:
m Instances: Standard Instances (Smart)
These instances come with a balance of CPUs and Memory. The more CPU cores, the higher the memory size that comes with the instances. These are general purpose instances and can be used as your initial training instance for testing. Of note is that none of the ‘m’ instances include GPUs.
c Instances: Compute Optimized (Super Smart!)
In these instances the balance is tipped towards CPU power. These instances are more appropriate for training jobs that consume more processing power and less memory, hence the name: ‘Compute Optimized’. These too, lack GPUs.
p/g Instances: Accelerated Computing (Smart and Fast)
GPUs are more efficient in computations as they can do it in parallel. However, in order to use these instances, we have to make sure that the training algorithm supports GPUs. Although, these instances are generally more expensive compared to previously mentioned instances, the reduction in time may result in lower overall price.
Factors for Instance Selection
Generally, when choosing which instance to utilize, one has to consider these factors:
Training Time
How fast do you want to train your model? This factor is rarely important, as in ML model training processes we are not usually time sensitive. But in case we have a deadline closing in, we might want to pay attention to this factor. Also, choosing a cheap instance while thinking that training time doesn’t matter is not always intuitive. Think for example of a hypothetical job that runs on an instance costing $0.5/hour, taking 2 days to complete while the same job can be done using a $2/hour GPU instance in two hours. The overall cost would be $24 in the first case and $4 in the second.
Pricing
I doubt if anyone would not care about cost optimization if they had the option. In a training job, we would want to optimize hardware utilization. A powerful GPU instance, would only waste resources if the training algorithm can’t utilize it fully (or at all). Likewise, an instance with high memory and low CPU power, would waste resources if CPU is utilized fully and memory gets used in a fraction.
How to choose the best instance
Intuition and Background Knowledge:
As we work on more training jobs, we acquire an intuition on the appropriate instances for different endeavors. In addition, the background knowledge on how a training algorithm works can help us narrow down our choices. For example, knowing that an algorithm works best on GPUs, we can focus our attention on g/p instance families. On the other hand, some algorithms can’t use GPUs for training. In such cases, choosing a GPU instance is an obvious waste of money.
Hardware Utilization Metrics
When you run a training job on SageMaker, Amazon Cloudwatch automatically tracks and monitors the hardware utilization of your training instances. This can easily be viewed via the ‘Training Jobs’ section of Amazon SageMaker Console. The picture below is an example for my personal job.
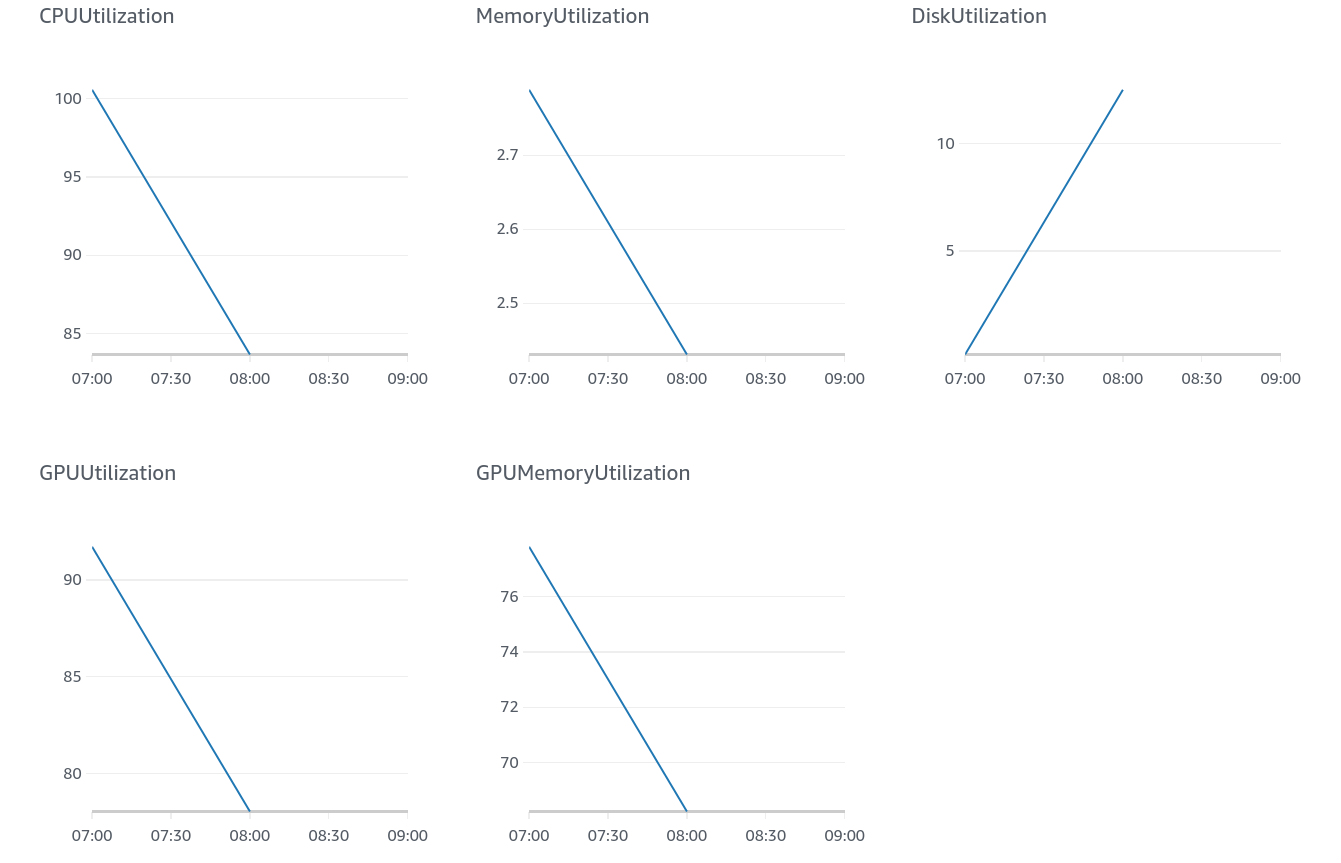
CloudWatch graphs for hardware utilization.
In this job, I have trained a deep learning algorithm using the PyTorch framework. Since Pytorch supports GPUs, I chose an ‘ml.p2.xlarge’ instance and my training took 5700 seconds in total. Since I am going to be charged $1.215 for each 3600 seconds, this job has cost me $1.92.
Looking at the cloudwatch graphs, I can see that the training job has taken 100% of CPUs. However, this is not as good as it looks. ‘ml.p2.xlarge’ comes with 4 virtual CPUs and so the CPU can be utilized up to 400%! The graph implies that approximately 3 vCPUs have been idle.
My first lesson: I could do this with an instance containing fewer vCPUs!
Memory Utilization graph shows that I have used a maximum of 2.8 GB of memory. This is when ‘ml.p2.xlarge’ comes with 61 GB of memory!!!
Second lesson: 3 GB of memory would suffice for such a job!
We will have a quick overview of the Disk Utilization graph. The storage volume is separate from the instance type and is defined inside your training notebook. However, it is good to know that the default value is 30 GB and this graph shows that I have at most used about 12 GB. I can specify this in my script, but it has nothing to do with the instance type. This storage is actually an Elastic Block Storage volume. More information on Amazon EBS can be found on EBS official documents
The two graphs on the second line show that my job has utilized GPUs efficiently. So no complaints there!
Final Conclusion: For my next training job, I should use an instance with approximately equal GPU power, fewer vCPUs and less Memory.
Taking another look at SageMaker Training Instances, I can see that an ‘ml.g4dn.xlarge’ instance seems to be more appropriate for my job. It still has 4 vCPUs but there is no GPU instance with fewer CPUs. On the other hand it comes with 16 GB of memory and the cost is 33% less than our previous instance. But is this all that matters?
Time-Price Combination
With further experimentation, one may notice that although hardware utilization has been optimized, the overall training time and price have increased! This can happen with GPU instances, as the architecture is different in ‘g’ and ‘p’ families. There is only one way to know which one works best for your training job. Experiment!
Practice Makes Perfect
In conclusion, to choose the best instance for your training, you have to pay attention to several factors, experiment and refine your choice. In this section, I am going to summarize all the steps we need to take in order to choose the best instance:
- Determining if training speed matters.
- Use intuition/past experiences and background knowledge to choose an initial instance. If you’re not sure, stick with the least expensive reasonable instance.
- Examine hardware utilization metrics using CloudWatch.
- Refine your choice.
- Experiment.
Advanced Optimization
After all, no single instance may fully suit your training job. As we saw earlier, you may not have the option of settling for an instance with fewer CPUs, as no such instance includes GPUs. One option in such circumstances may be scaling out, that is dividing your training into multiple jobs and using multiple instances. But more on that later!