Serverless Architectures - Pause, Think, and then Redesign.

‘Computer architecture, like other architecture, is the art of determining the needs of the user of a structure and then designing to meet those needs as effectively as possible within economic and technological constraints.’ - Fred Brooks, “Planning a Computer System: Project Stretch”, 1962
Introduction
In this blog post, we are going to talk about serverless architectures and why a software designer should think before creating their tech-stack. When it comes to designing solutions we often come across a lot of questions regarding provisioning, costs, and durability of the intended architecture. In that context, this article provides you with an appetizer before you start thinking about the entree.
Considering the big investments in serverless made by the top three cloud vendors (AWS, Google Cloud, and Microsoft Azure) over the last few years, we will briefly touch on what is serverless and how easy it is to deploy and provision resources. We’ll look at various factors that influence your serverless design and why you should consider these factors before designing your application. We’ll also provide you with a high-level architecture that we designed to solve a use case for one of our clients in the area of data engineering. And since nothing is absolutely flawless, we will also enlist some drawbacks of serverless as well.
At its re:Invent conference, AWS today announced that four of its cloud-based analytics services, Amazon Redshift, Amazon EMR, Amazon MSK and Amazon Kinesis, are now available as serverless and on-demand services. ~ re:Invent 2021
Why Serverless and what are the various resources available within it?
The term ‘Serverless’ refers to applications that are built with the notion that the organization is not responsible for maintaining the hardware or the software server-side processes involved in it. It means to outsource these responsibilities to someone else. The word ‘outsourcing’ often comes with a need to trust the outsourced party and in recent years AWS has done a terrific job in being a secure, trustworthy partner in “adopting serverless services for increased agility throughout your application stack” (why you should use serverless). “Serverless" does not mean no servers at all. It uses virtual machines (Micro VMs) underneath but on a smaller scale as compared to EC2 instances. In layman’s terms, going serverless means developing and innovating more without thinking about maintaining your resources.
Mike Roberts in his article has categorized serverless architectures into two different avenues (which are sometimes overlapping):
Backend as a Service (BaaS) Applications that use third-party cloud-hosted services to manage server-side logic. Some examples of third-party services include identity and authentication as a service (AWS Cognito), logging as a service (Logsense, Amazon Elasticsearch Service) and analytics as a service (Amazon Kinesis).
Function as a Service (FaaS) Applications that involve server-side logic to be implemented by developers running in stateless mode. Stateless mode is often the preferred way to go since it offers us the ability to build applications where the server and client reside loosely coupled and hence are more tolerant to failure, disruptions, and can act independently. AWS Lambda, Google Cloud Functions and Azure Functions are examples of FaaS implementation.
What do you get with Serverless applications ?
You don’t have to care about the infrastructure of the applications. Neither its provisioning nor maintenance.
You don’t have to deal with failures related to scaling up/down of your application.
You only pay for what you use.
You don’t have to worry about availability since the service provider (for example AWS) takes care of it under the hood.
In short, if an organization is thinking that going ‘serverless’ requires an overhaul of their system and resources, it actually isn’t. With a few best practices and even fewer lines of code serverless applications can be made fully functional. Most serverless applications have an event trigger associated with it, a compute engine (function) that takes care of the processing, and a sink (data store) or an invocation of another service.
The following image shows the three basic components needed for a serverless architecture [1]:
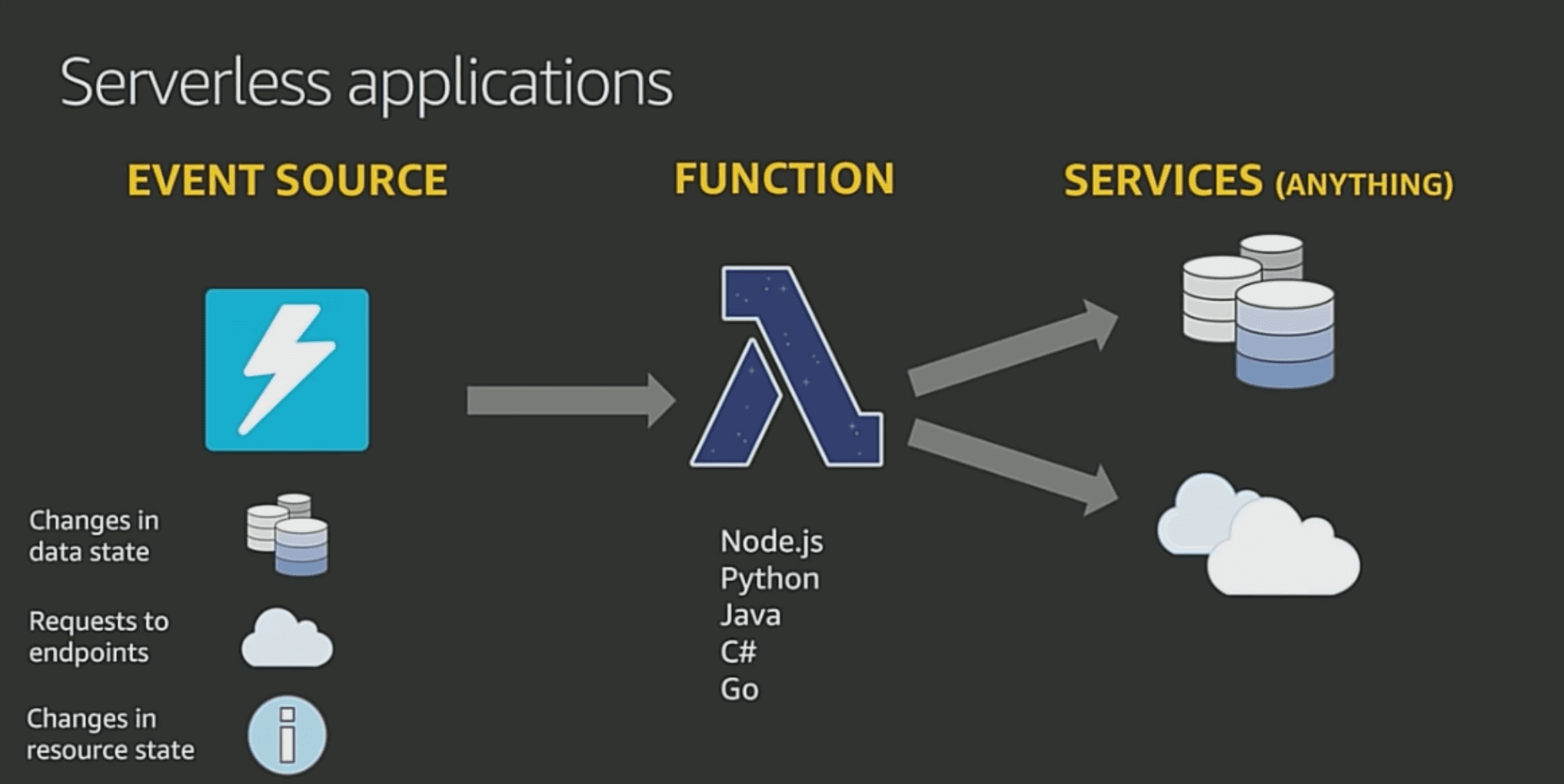
The types of resources are available to us via serverless computing framework in AWS are:
Compute Engine : Lambda, Fargate.
Application Integration (Event trigger): Eventbridge, SQS, SNS, etc.
Data Store: S3, DynamoDB etc.
And to give you an example of how ‘simple’ it is to deploy a serverless application, the following is an example of a serverless file that deploys an API endpoint with the help of a flask application and uses Lambda to process requests made to this API. We will not go into the details of how to deploy serverless applications and why we used the options below because that is beyond the scope of this post (here is a link to demonstrate the deployment of a serverless application in aws). However, it is important to note that we have added monitoring (AWS Cloudwatch), key encryption (AWS SecretsManager) as part of the code above which may or may not be required depending on the use case. The following is an example of the entire code snippet we used to deploy this application in AWS :
service: serverless-flask-app
frameworkVersion: "2"
plugins:
- serverless-python-requirements
- serverless-wsgi
custom:
wsgi:
app: app.app
packRequirements: false
pythonRequirements:
dockerizePip: non-linux
provider:
name: aws
runtime: python3.9
lambdaHashingVersion: 20201221
iamRoleStatements:
- Effect: "Allow"
Action:
- "s3:*"
- "cloudwatch:*"
- "logs:*"
- "apigateway:GET"
- "apigateway:POST"
- "secretsmanager:GetSecretValue"
Resource: "*"
region: eu-west-1
functions:
app:
handler: wsgi.handler
events:
- http: ANY /
- http: "ANY {proxy+}"
How to decide which Architecture to choose?
Now that we have demonstrated briefly just how easy it is to deploy applications using serverless we should address the more fundamental question. Ideally, this is a two-part question and the first part deals with the type of serverless invocation method. Depending on the event trigger and the type of use case, there are three types of serverless invocation methods [2]:
Asynchronous
Synchronous
Streaming

Scenario 1:
You have a requirement from the client that every request made by the client should be met by a response in return. In essence, there shouldn’t be a considerable lag between the requests-response and every request has to be served. This is where you should choose synchronous invocation.
Scenario 2:
You want to serve requests from your client but ideally, you don’t want to keep them waiting. You want to be able to process these requests and let the client know after the processing has been done through a notification (alert). Asynchronous invocation is the answer to this use case.
Scenario 3:
Suppose you have a use case in which the priority is that you have to keep up with the pace of data coming from the upstream, ensure data capture (persistence) and load the data in downstream applications. Streaming application is the solution to this and AWS Lambda supports them (you can find more about how to deploy them in this post). In the end, the question of whether you should go ahead with building streaming applications is determined by how ‘real-time’ you want your application to be(difference between batch processing and real-time).
Each scenario will have a different invocation method (microservice call) associated with it. And this is where we come to the second part of the two-part question, namely what type of microservice you should choose for your serverless application and what factors you should decide that on. We are going to use Lambda, SQS , and SNS as the components of our serverless architecture to understand how these factors affect your overall architecture.
There are broadly five important factors to think about while making these architectural decisions :-
Scale - How many requests do you want to serve at a time ? For instance, AWS Lambda API offers up to 3000 requests (varies with region) at a given point in time and is shared for all functions in a region. SNS and SQS are both auto-scaling in nature (will scale up according to load) but you can also set a concurrency limit to this.
Durability - How important is it for you to handle failures without manual invention ? Lambda is highly-available but it does not offer you durability. So clients need to handle failures/retries themselves (unless you are smart enough to set up reprocessing). Compared to this both SNS and SQS stores all the messages they receive and are durable to an extent (multiple copies across multiple regions).
Persistence - How often do you expect a failure and hence do you want a persistent architecture? Herein you might want to consider the important differences between a stateless and stateful architecture.
Retry/Failure Handling - Synchronous invocations of Lambda are client dependent for retries. But for asynchronous invocations, Lambda retries twice. Similarly, if you setup SNS with Lambda it will do multiple retries followed by an exponential backoff (more on SNS delivery retries can be found here). For SQS, it is a slightly different story as the message remains in the queue until a successful Lambda invocation. So, the question is how do you want to handle failures and retries?
Pricing - The pricing for each service is available in the AWS calculator but the key point here is most of these microservices are billed per request and there are no extra invocation charges for instances like SNS, Lambda. For example, Lambda invocation costs 0.2 USD per request while SNS costs 0.5 USD per request (where 1 request corresponds to 64 KB of delivered data). However, it is important to set up monitoring for your application as your estimated costs may not match your actual costs if the Lambda keeps failing (or you manage to create an infinite loop inside the function).
So, what do I do with all this information ?
When you think of designing a serverless architecture, make sure your system is loosely-coupled and fail-fast. As mentioned earlier, choosing asynchronous architecture has its merits in this scenario.
Try to fan-out properly. Fanning Out is when messages are passed to multiple endpoints from a single source at the same point in time. SNS is an extremely good solution in this regard since it offers durability with a low cost and high persistence.
Avoid Bottlenecks. Consider a scenario where you have to use a Lambda function to do a heavy calculation and load the data is S3. Instead of directly calling the Lambda function, add a SQS queue and to help protect the downstream service invocations.
Since serverless applications run on micro VMs it would be wise to avoid infinite loops in your Lambda functions. Using best practises like setting up cloudwatch alarms for your Lambda-functions and reserved concurrency will certainly help avoid recursive patterns. These are some of the considerations we made while designing a serverless application for one of our clients.
An Overview of how these choices were made with a Customer Story
We decided to use a serverless architecture for a use case provided to us by one of our clients. The problem definition was to extract information from emails generated when a customer interacts with an online advertisement. And to feed this extracted information to businesses using a data pipeline. The basic requirement was to reduce the response time between the customer and business by automating information extraction from these emails. We came up with a solution involving an event trigger (SNS) , a data store (S3) and a compute engine (AWS Lambda).
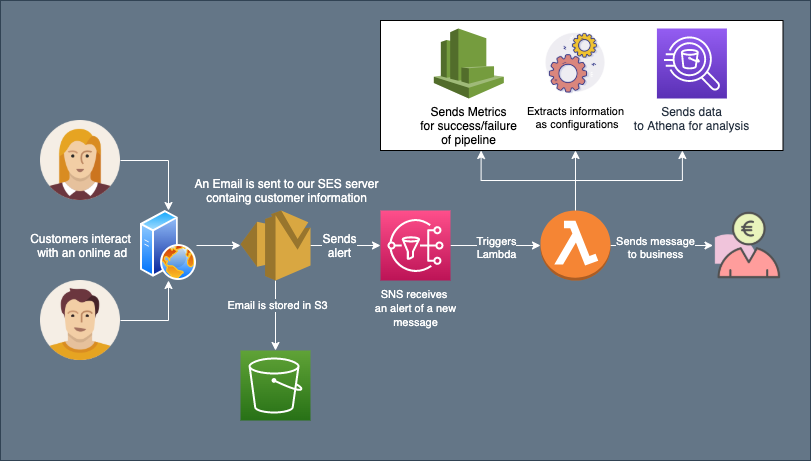
The diagram above shows the high-level architecture we used. Every piece of the puzzle including automated extraction of information as configurations (using Dynaconf), raising SNS alerts, sending metrics to Cloudwatch was achieved through automated serverless deployment.
We managed to remove the manual process of notifying the business when a customer interacts with an online ad and also reduced the response time between customer and business by a factor of 10. In addition, we managed to send the data to external systems through Kafka and also keep track of the messages by creating a data pipeline. This data pipeline takes the messages in raw-format , anonymises the sensitive information and stores them in Athena solely for the purpose of future analysis.
So far, we spoke about serverless architectures in the context of data engineering or software engineering. But it is also possible to make your machine learning (ML) models ‘serverless’. Production-ready ML models come with high overhead costs on computation and memory requirements (assuming you are making something worthwhile). Keeping that aside, you can reduce or optimize your inference costs by making the inference architecture serverless (more on this in our upcoming posts).
Conclusion
In the realm of software development, one should be wary of using new technology ‘blindly’. It is wise to note that serverless, like others before it, has its drawbacks. While some of these drawbacks on tooling and configuration have been worked on (over the last couple of years) largely with the effort of Amazon’s Serverless Application Model (AWS SAM), some others like integration testing (for BaaS) needs improvement.
Some of the drawbacks that we (as developers) have faced with serverless:-
Cold Starts - In practice, it needs some time for a Lambda to handle the first request. This is because the platform needs some time to initialize internal resources. One way of avoiding this is sending periodic requests to your function to keep it active.
Some FaaS implementations such as Lambda do not provide out-of-the-box tools to test functions locally. Since Lambda is billed per request it may not be economical to test your functions on the cloud. Solution : create your own testing environment locally and use Lambda only when you are sure about the end result (in any case the invocation cost is quite low).
Vendor Lock In - Although serverless provides the pathway to deploy code very easily, it also locks in the architecture and the service to the specific vendor like AWS. In hindsight, it is not a problem if you are working with a single vendor (although you are quite dependent on the platform itself for resources). But, it could be an issue if you suddenly want to switch to a new provider (FaaS implementations are not compatible with respect to service providers).
In conclusion, we have shown how easy it is to deploy applications via serverless and also highlighted several factors you should consider while designing your architecture. We hope you have enjoyed reading this post and please feel free to reach out to us in case of questions, concerns, support or feedback.
Figure References :