Paraphrasing and Style Transfer with GPT-2
Since their introduction in 2017, transformers have gotten more popular by day. They were initially proposed in the paper Attention Is All You Need. In Natural Language Processing, a transformer is a structure that helps perform the seq2seq tasks (te...

Since their introduction in 2017, transformers have gotten more popular by day. They were initially proposed in the paper Attention Is All You Need. In Natural Language Processing, a transformer is a structure that helps perform the seq2seq tasks (text generation, summarization, etc) previously performed by Recurrent Neural Networks – later to be improved and optimized in LSTM architecture – in parallel.
GPT-2
One such transformer, introduced in 2019 by OpenAI team, is GPT-2. Based on the team’s claim, this transformer has been trained on 40 GB worth of text from 8 million web pages. At the time of writing this post, GPT-3 from OpenAI is out, but we experimented with the lighter version of GPT-2.
Text Generation
Essentially, what GPT-2 does is to generate text based on a primer. Using ‘attention’, it takes into account all the previous tokens in a corpus to generate consequent ones. This makes GPT-2 ideal for text generation.
Fine-Tuning
Creators of GPT-2 have chosen the dataset to include a variety of subjects. This makes the pre-trained version ideal for general text generations. So what if we wanted to generate text based on some specific corpus? GPT-2 can actually be finetuned to a target corpus. In our style transfer project, Wordmentor, we used GPT-2 as the basis for a corpus-specific auto-complete feature. Next, we were keen to find out if a fine-tuned GPT-2 could be utilized for paraphrasing a sentence, or an entire corpus. In our endeavor, we came across Paraphrasing with Large Language Models paper. Basically, what the authors have done is combining the original and the paraphrased sentence. They do so by placing the original sentence and the paraphrased sentence on one line, divided by a special token. Finally, we decided that the best result could be achieved through T5, another powerful transformer. Yet here we go into details of what we did to achieve this goal using GPT-2.
Shakespeare Paraphraser
Dataset
The main challenge in designing a style-specific paraphraser was to align general sentences/corpora with their style-specific counterparts. In our quest for a suitable dataset, we found SparkNotes, a website designed to help users understand heavy works of literature. We used their guides for Shakespeare plays, which consisted of original dialogues and their equivalent in modern English. We used a scraper on all Shakespeare plays and saved all the aligned sentences in a csv file. We then cleaned our dataset and made it ready for action. The final dataframe looked like this:

Feed the GPT-2
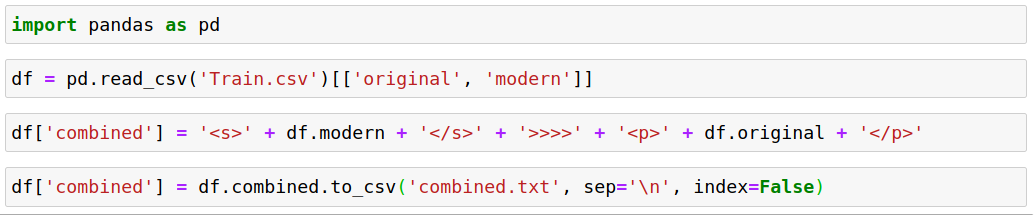
Now to make our dataset ready to be fed to GPT-2, we combined our ‘modern’ column enclosed in <s> and </s>, followed by the unique token of ‘»»’, and then the ‘original’ column enclosed in <p> and </p>. Below is the code snippet used for this:
Fine-tuning GPT-2
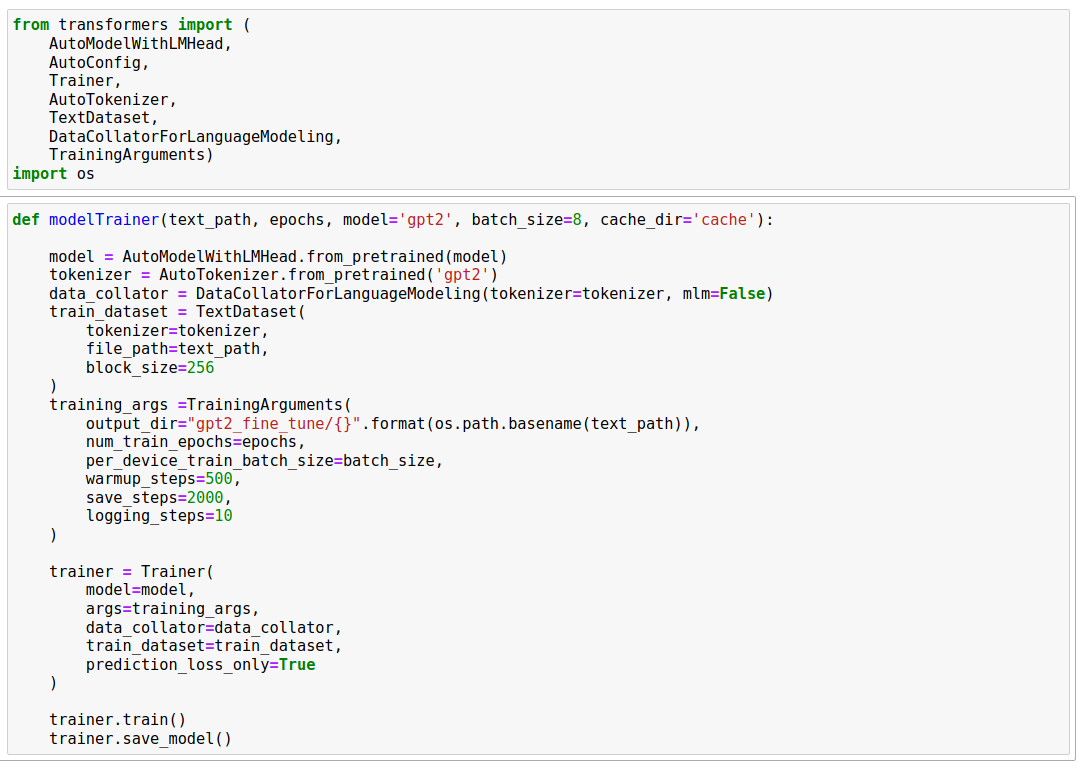
And then the last step: simple fine-tuning of GPT-2. For this we used the ‘transformers’ library from HuggingFace. Depending on your hardware such a code could be tweaked to finetune GPT-2 based on any text file.
Test-Drive
After calling the modelTrainer function, the model gets saved to the ‘output_dir’ folder. We moved it to a folder named ‘shakespeare’. Now is the time to test our fine-tuned model. We start by importing dependencies and loading the model. Since we have not trained GPT-2 from scratch, we use GPT-2’s default tokenizer.

We define a paraphraser function to manipulate the input according to our initial dataset manipulation. This way we make sure that GPT-2 follows our sequence with the paraphrased version. Now the generator function gives out our original sequence and generates the following tokens. The output is a list of dictionaries (based on how many outputs we requested). The value of the ‘generated_text’ key, is our target. As you can see the output is dirty and following the pattern of the dataset, it goes on to generate additional sentences. Of course, we can define a ‘max_length’ parameter in our pipeline, but it comes with the possibility of an incomplete paraphrase.
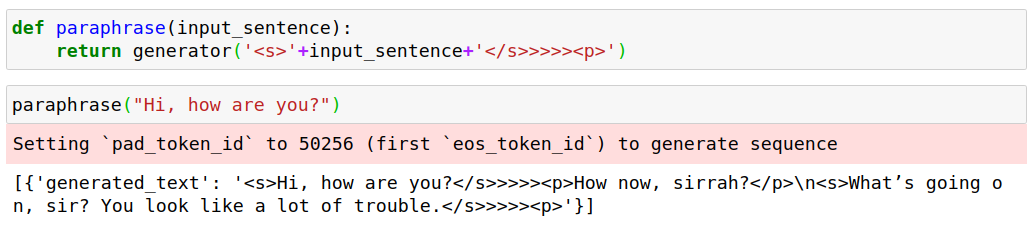
So we define another function to trim the output:

Or better yet, 2 in 1:

Nice! Now let’s see how Shakespeare would have said some sample sentences:
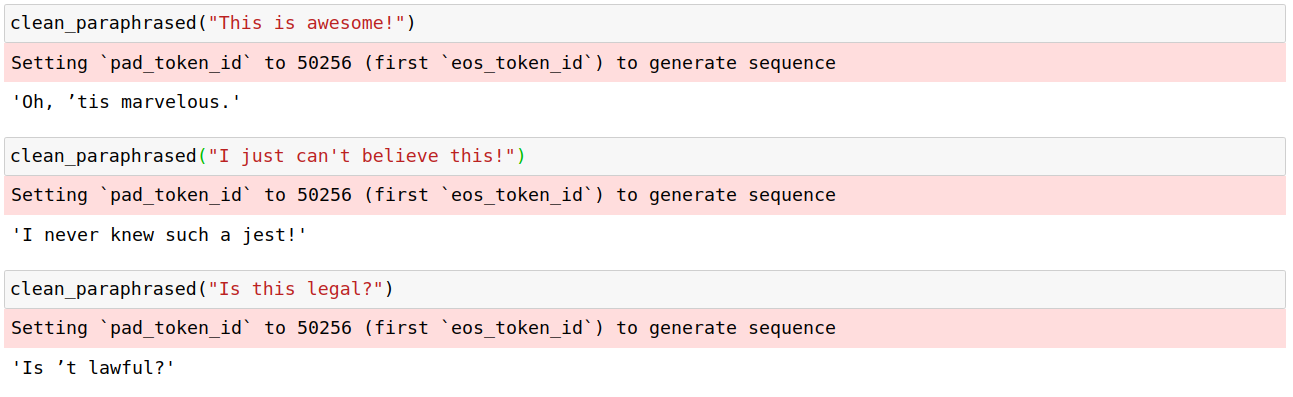
In the end, we used T5 for our purposes as mentioned here, but it was nice to see GPT-2 could also be utilized for the same goal. What use-cases can you imagine for such paraphrasers? What would you build on top of it? Share it with us! We appreciate your interest!