Tiny caveats of using different S3 Schemes on AWS Glue
Introduction Suppose you have a scenario in which you want to transport data from one point to another. AWS Glue, being a fully-managed ETL service makes it a go-to choice for being the data integration/transportation assistant for any such use case....
Introduction
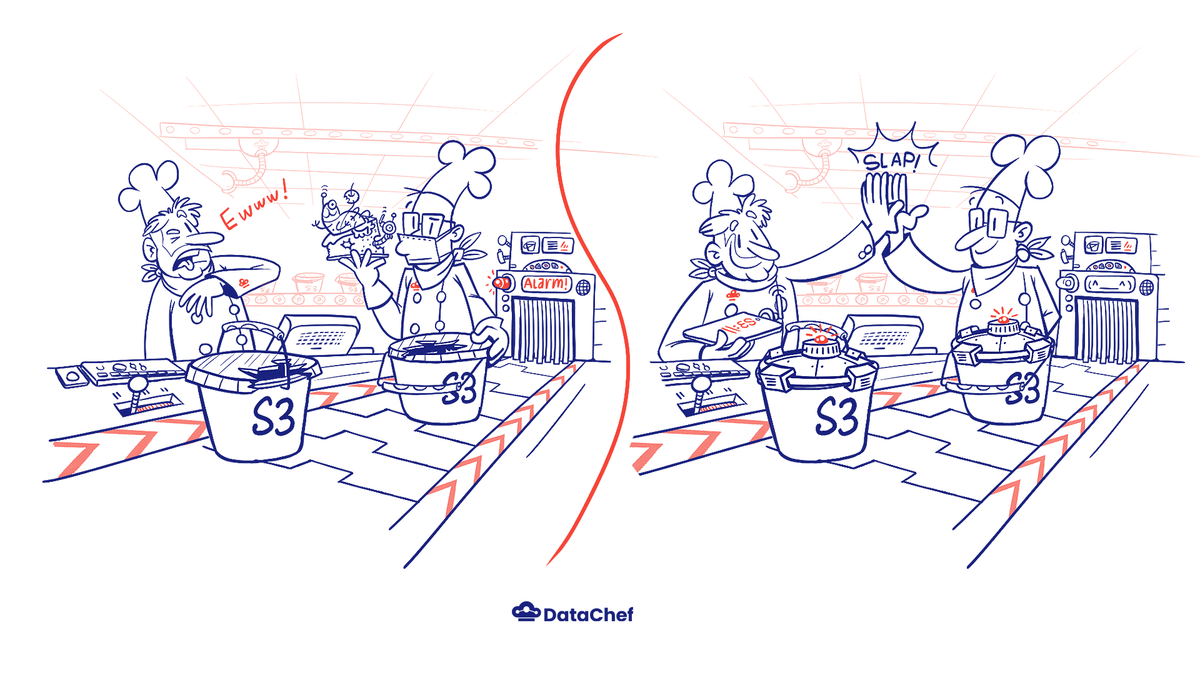
Suppose you have a scenario in which you want to transport data from one point to another. AWS Glue, being a fully-managed ETL service makes it a go-to choice for being the data integration/transportation assistant for any such use case. Additionally, let’s assume you want to use S3 to store your data objects in the form of Delta files. Some common advantages of S3 as your data-storage service is its high-availability and security. Since security is a concern for all of us, we generally tend to have a uniform key encryption strategy for all kinds of data storage objects in S3. We found out recently that getting a uniform key encryption strategy may not be a piece of cake.
We, at DataChef, use S3 to store our data objects (mainly Delta files) and AWS Glue to primarily run data workflows. While working with AWS Glue and S3, we came across an interesting scenario that could be useful to someone facing this issue or a similar bug. We use s3 schemes on AWS Glue to write to Delta and in one such data pipeline we came across this error:
java.io.IOException: The error typically occurs when the default LogStore implementation,
that is, HDFSLogStore, is used to write into a Delta table on a non-HDFS storage system.
And the solution is to use the community-developed s3 scheme s3a://. But here is the catch. For Delta files returned from Spark jobs, s3a:// uses a different key-encryption strategy as opposed to s3://. And therein lies the problem of key encryption inconsistencies (namely custom KMS key encryption as opposed to AWS s3’s default key encryption) for different platforms.
How can we access S3 resources?
Amazon S3 supports RESTful architecture and every resource in S3 can be accessed programmatically through a unique URI or a URL. One can access S3 resources through URLs using one of the following ways:
virtual-hosted-style access : Bucket name is part of the domain for example: https://bucketname.s3.region.amazonaws.com
path-style access : Bucket name is not part of domain for example : http://s3.region.amazonaws.com/bucketname
Moreover, one can also access S3 objects through other AWS services such as AWS Glue, AWS Lambda programmatically through a URI scheme. They require specifying an Amazon S3 bucket name to the URI scheme: s3://bucket_name. In relation to this, there are two other S3 schemes: s3a and s3n.
What is the difference between s3, s3a, and s3n?
s3n:// A native filesystem for reading and writing regular files on S3. The advantage of this filesystem is that you can access files on S3 that were written with other tools and vice-versa.
s3a:// Hadoop’s successor to s3n and is backward compatible with s3n. It also supports accessing files larger than 5GB and provides performance enhancements.
s3:// A block-based file system supported by S3. Files are stored as blocks just like in HDFS.
“Since Hadoop 2.6, all work on S3 integration has been with S3A. S3N is not maintained except for security risks —this helps guarantee security”.[1]
KMS Key Encryption for S3 Buckets
S3 has a bucket policy enforcing encryption on all the data uploaded to the bucket with the KMS key. This allows any user to encrypt the data they upload with their own KMS key.
What happens when we try to access s3 buckets using the s3a scheme for writing to Delta Files?
Delta Lake provides ACID guarantees for any storage system (such as S3) it accesses. Delta Lake uses the scheme path (s3a://) to identify the storage system dynamically and uses the corresponding LogStore implementation to provide transactional guarantees. The LogStore API is responsible for providing the ACID guarantees (such as atomic visibility, mutual exclusion) for reading and writing to Delta. However, one interesting fact we found was that for .parquet files, Hadoop uses the default customer-managed KMS keys as configured for the bucket. But when we use something other than s3://, Hadoop will revert to using AWS managed AWS/s3 key for Delta log/manifest files.
Lessons Learned: Maintain the platform integrity
The use of s3a:// is deprecated and no longer supported by AWS. Hence it is always encouraged to use the s3:// scheme for accessing S3 through AWS Glue or other AWS services.
If you have to use s3a:// then it is important to specify the server-side encryption key. This can be set using the following option -> fs.s3a.server-side-encryption.key.
Use the following code in Spark builder part of the script which will allow the class to write to S3 using s3a://.
.config("spark.delta.logStore.class",
"org.apache.spark.sql.delta.storage.S3SingleDriverLogStore")
In Closing
In conclusion, we at DataChef, are looking to solve interesting problems smartly through the use of AWS-managed microservices (apart from anything and everything that is open-source). I believe it is our responsibility to share information that might benefit someone who is looking to solve a similar problem. Please feel free to reach out to us, in case you have encountered this, or a similar problem and share your thoughts.
References
[1]: S3 Support in Apache Hadoop