How We Paid 14,000$ Bill to AWS and Why We Liked It!
Introduction In the world of AWS, it’s easy to set up any infrastructure you want with a click, and because of this simple reason, it’s too easy to lose track of what you are currently running. The Story At DataChef, we have several AWS accounts for ...
Introduction
In the world of AWS, it’s easy to set up any infrastructure you want with a click, and because of this simple reason, it’s too easy to lose track of what you are currently running.
The Story
At DataChef, we have several AWS accounts for internal usage and testing. We don’t deploy any long-running tasks on these accounts.
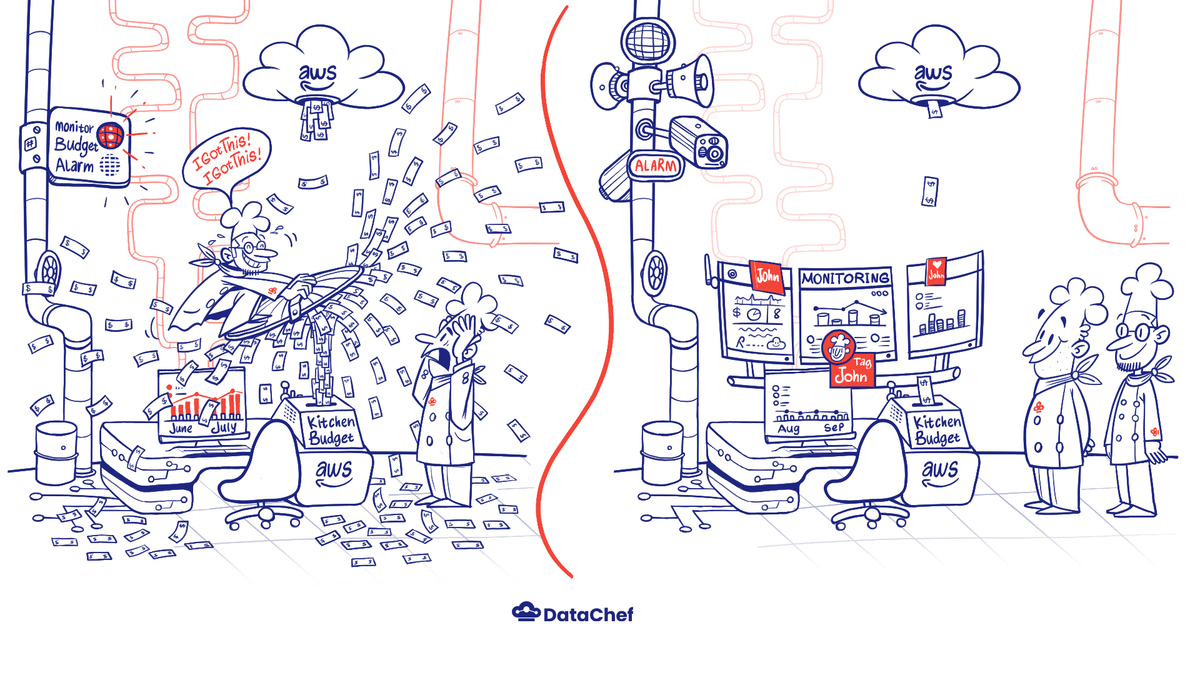
The other day I was testing an event driven system on AWS EventBridge; the system has two sets of components that get triggered by events and then publish another event. A software bug in the system caused it to process an event forever and created a loop in the whole system. This bug led to eating as many resources as possible in the period it was running, and we ended up with a 14,000$ bill for it.
Issue Discovery and Reaction
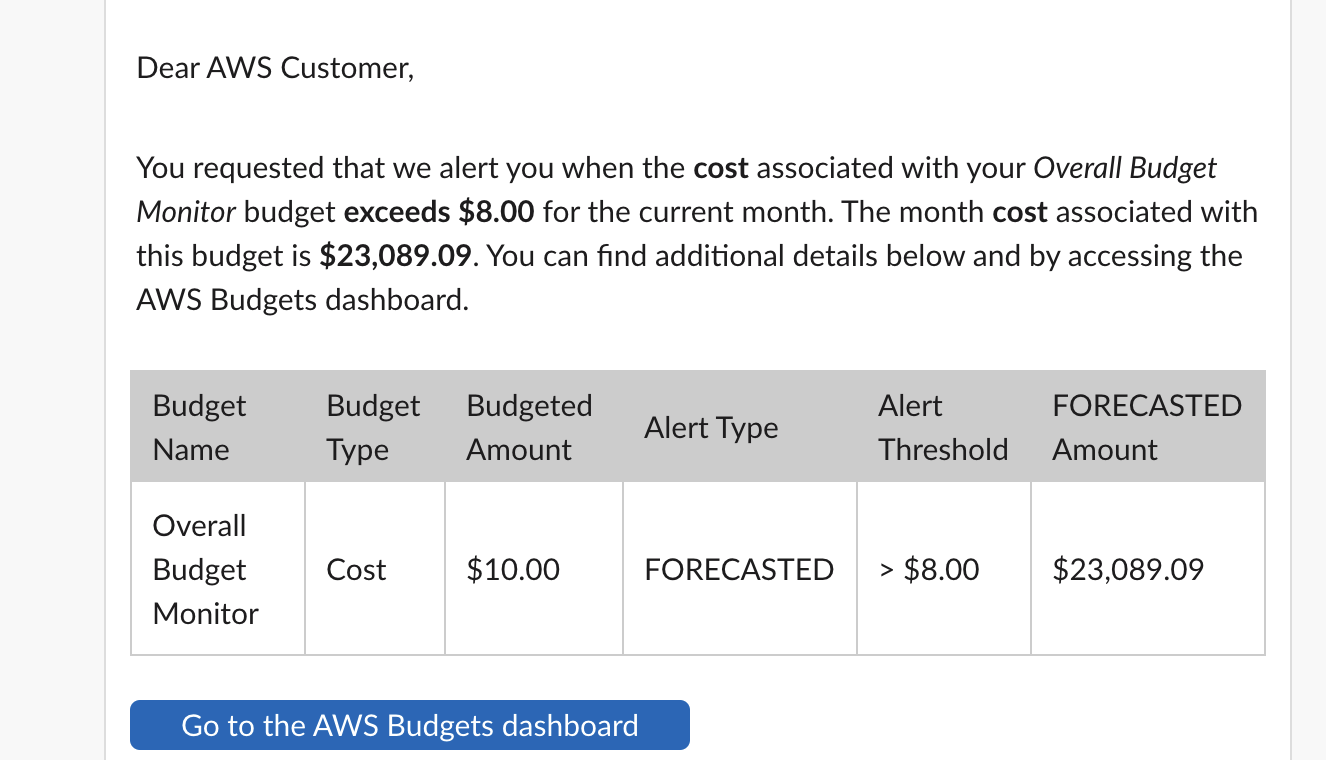
The Email
We have a Slack channel for “aws-budget” On July 1st, 2021 (16:15 PDT), there was a message from the AWS budget mentioning that a 10-dollar budget trigger went off with a 23K forecasted amount.
Finding the Root Cause
After getting this message, I jumped into the cost explorer to see what was happening.
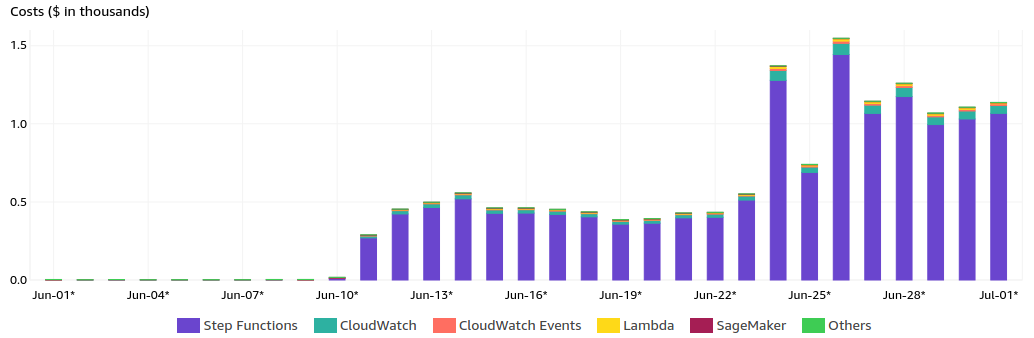
It’s evident from the charts that step functions were running more than they should have. Another bad news is that these step functions did not have any tags associated with them. At this moment, I did not know what system caused this. After checking the Lambda function executions, I found one that was executed several times. It was clear that this system might have been the root cause. I immediately stopped the system and tried to recreate the situation to verify my hypothesis.
Application Bug that Caused Resource Eating
As I already mentioned, the system has components that communicate using events. A simple demonstration of this would be the following diagram:
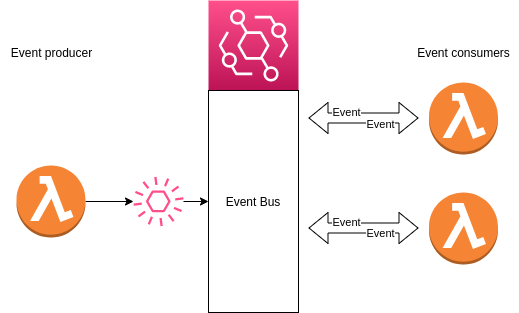
In this system, Lambda functions subscribe to an EventBridge rule and get triggered by each event that matches the rule. A single event is defined like this:
{
'Source': 'App',
'EventBusName': 'default',
'DetailType': 'TaskCompleted',
'Detail': null
}
You can define your rules based on these attributes, like specifying to consume all the events from the source “App.”
In our case, the bug was in events published from the consumer side and the rule that triggered consumers. Our matching rule matched the rule that we produced, which led to infinite processing of that event. However, the system worked fine, and you could see the result, but this bug was eating resources behind the scenes.
Why Hadn’t We Noticed the Problem Earlier?
There are several takeaways from this incident, but the most important one is this question: if something is wrong, you should know it as soon as possible, right?
The problem was because our budget control was not set correctly for our usage.
First, the threshold was set pretty low, and since it was often reached, we assumed it was safe. Secondly, we only had one monthly budget control alarm. So, when the cost went up in mid-June, nothing else was sent out by the budget control. The next one that came out was on July 1st, and the only eyebrow-raising piece of information was that huge forecast.
How Do We Avoid it in the Future?
After this incident, we investigated the root cause and what caused the delay between the incident and finding out about it. Here is a list of further steps to prevent this from happening again.
Tagging Resources From the Beginning
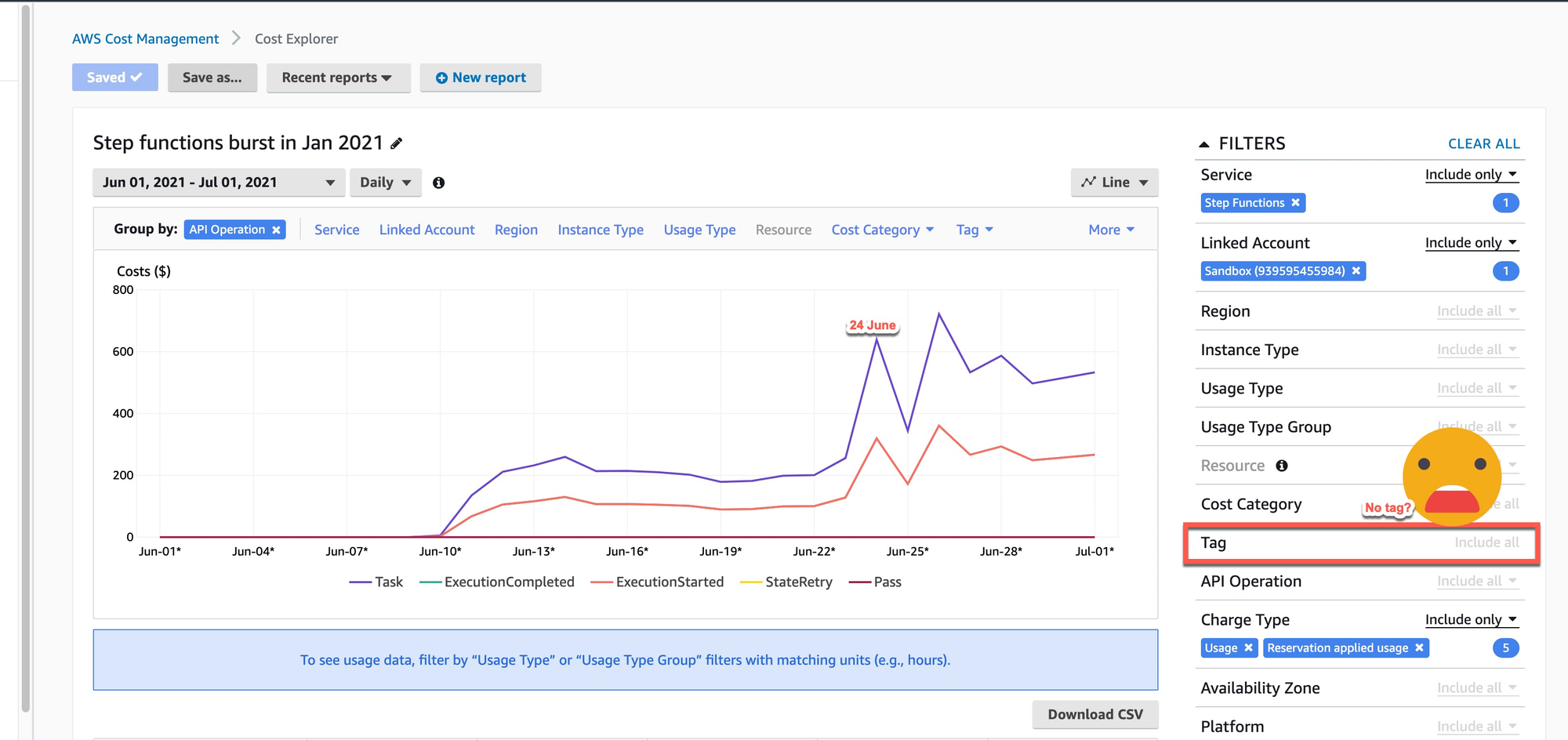
By tagging resources, it makes it much easier to check service costs in cost explorer. We want to make sure everyone tags created resources, but people can forget. We are working on a new recipe to address this problem. With proper tagging, we can always check how much the system costs (and whether our estimation about this was correct or not) and avoid having costs that are hard to discover.
We started using a tagging strategy for sandbox accounts. Although it’s not a very active account, having these guardrails is a must from the start. Remember when many MongoDB databases got hacked because people believed that MongoDB only listens to local connections?
We started tagging our resources in the simplest possible way with one mandatory tag, owner:name, and one optional tag, project, categorized as business tags. If you’re picky about this, there is a whitepaper from AWS, which describes all you need for a robust tagging strategy.
Improve Budget Alerting
At the time of this incident, we had our billing alarms set, but from this experience, we found out some things are not correct:
- Our alarm only notified us monthly (that’s why we found out about the costs some days later)
- Our budget was not realistic with our usage
We could have taken action much sooner about this problem and prevented it from happening with proper alerting. After this incident, we now have a daily budget to know if something is wrong the day after, alongside a monthly forecast alert to get notified if the cost forecast will exceed our threshold for the month.
If you don’t have a budget alerting yet, navigate to Budgets in AWS and set it up now.
Monitor Resource Usage of an Application
After running something on AWS, you can guess how much it will cost to run it, but always check it with the Cost Explorer dashboard to ensure it. With proper tagging in place, it is a very straightforward task to do. Remember, this type of resource eating can happen in other cases too. For example, if a Lambda gets triggered by files uploaded to a bucket and uploads files to that same bucket, there will be a similar problem.
In Closing
We received a huge bill from AWS, and we liked it. We learned invaluable lessons about securing our AWS accounts against unwanted costs by setting up the right kind of guard rails by default.
We hope that the lessons it taught us will benefit you too after reading this post mortem.