DutchRank.ai: Why the Netherlands Needs Its Own AI Arena
DutchRank is an open arena where Dutch speakers blind-test AI models head-to-head, turning gut feel about "which model sounds best in Dutch" into a real leaderboard.



Picking an AI model for a Dutch-facing product should be a simple exercise. Try a few. Compare the output. Choose the best one. In practice, anyone who has done this knows it falls apart quickly.
The differences between models in Dutch are real, but they're hard to pin down. Sometimes a model clearly nails it. Sometimes a model you'd written off surprises you. Most of the time the gap is close enough that the impression depends on which prompt was sent last, and which colleague happened to be in the room when the output was read.
That's a strange position to ship a product from. And it's where a lot of teams sit today. Companies, government institutions, healthcare providers, schools, all picking an AI tool for a language with 25 million native speakers, mostly on gut feel.
For English, the tooling to answer this question is mature. For Dutch, it hasn't been. That's the gap DutchRank exists to fill.
Two complementary signals
A healthy AI evaluation ecosystem rests on two pillars, and they answer different questions.
The first pillar is standardized benchmarks. MMLU, HellaSwag, ARC, Dutch CoLA, SICK-NL, and similar datasets. These tell you about capability. Can the model reason? Does it know facts? Can it parse grammar? Benchmarks are reproducible, fast, and objective. You get a number, and you can compare models apples to apples. They are genuinely valuable work, and DutchRank uses them as one input through its Automated Evaluation track.
The second pillar is arena-style human evaluation. Blind, head-to-head comparisons judged by native speakers. This tells you about usability. Given two real responses, which one do people actually prefer? Arena evaluation captures qualities that capability benchmarks aren't designed to capture: tone, fluency, idiomatic phrasing, cultural fit. It's also harder to game, because there is no fixed test set to overfit to.
Neither pillar is sufficient on its own. A model can score well on benchmarks and still feel robotic. A model can win arena votes and still be factually unreliable. Together they approach something closer to the truth.
A concrete example from work on lower-resource languages makes this split easy to see. Across many languages in a position similar to Dutch, gpt-oss 120B tends to be the stronger reasoner. It handles multi-step problems and structured tasks more reliably. Gemma 3 27B, on the other hand, tends to produce more natural, fluent prose in the target language. Same task, same language, two different "best" models depending on whether you care about reasoning or about writing. A leaderboard that measures only one of those axes will miss half the story.
What native speakers catch that scores can't
A lot of what makes Dutch sound like Dutch is invisible to automated scoring and obvious to a native reader.
Idioms are the cleanest example. "It is raining cats and dogs" translated literally becomes "Het regent katten en honden." A Dutch speaker would say "Het regent pijpenstelen." Both are grammatical. One sounds natural. The other doesn't. That difference shows up in two seconds for a Dutch reader and almost never in a numeric score.
But it's not just about getting idioms right. The same nuance applies to real-world prompts. The Dutch text people actually need from AI looks like customer questions, internal memos, policy drafts, and patient summaries. Arena evaluation is open-ended by design, which means it covers exactly that surface, judged by the kind of people who would read this writing for a living.

What DutchRank actually does
DutchRank is an open evaluation platform where Dutch speakers compare AI models head-to-head in blind battles.
You type a prompt. Anything. A simple question, a complex request, a creative writing task. The interface works in Dutch and English.
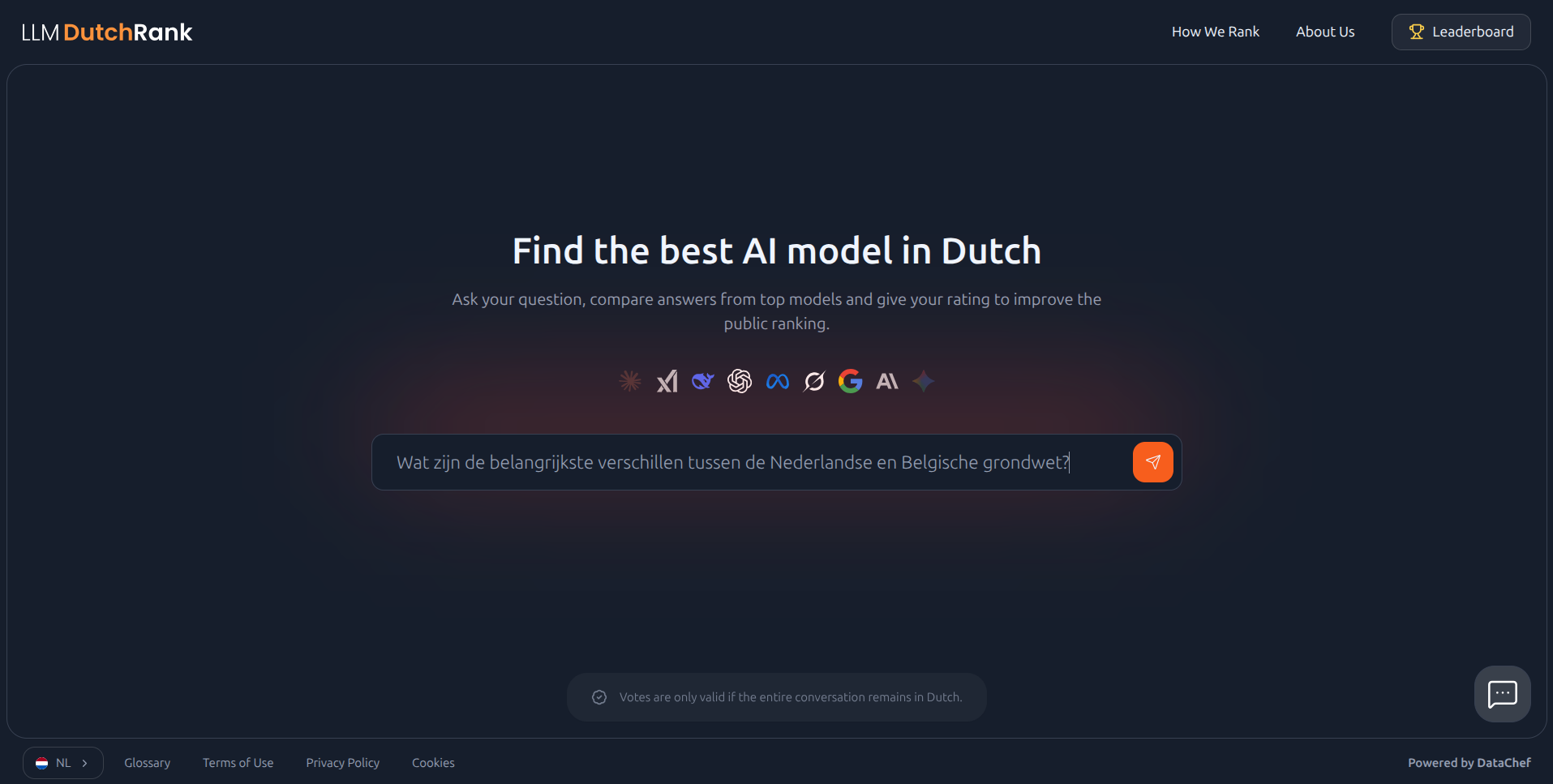
Behind the scenes, DutchRank picks two models at random. You see only "Model A" and "Model B," streaming their responses side by side in real time.
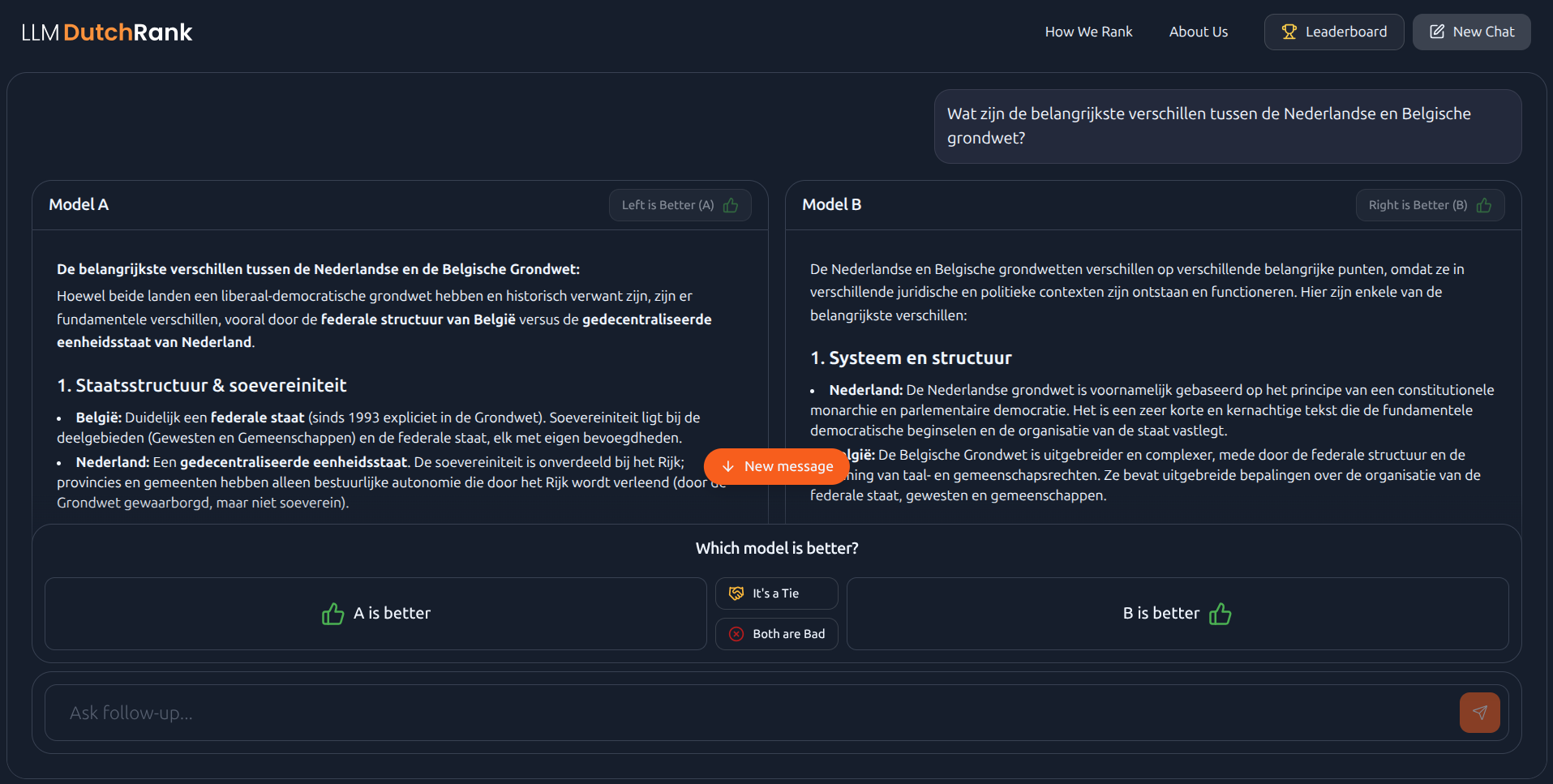
You watch them work through your question, token by token. Some write more formally. Some get the grammar right while others stumble on a de/het choice.
After reading both, you pick a winner, call it a tie, or mark both as bad. No scoring rubric. No rationale required. Just one question: which one sounds better to you?
Only after voting does DutchRank reveal which models were behind the curtain.
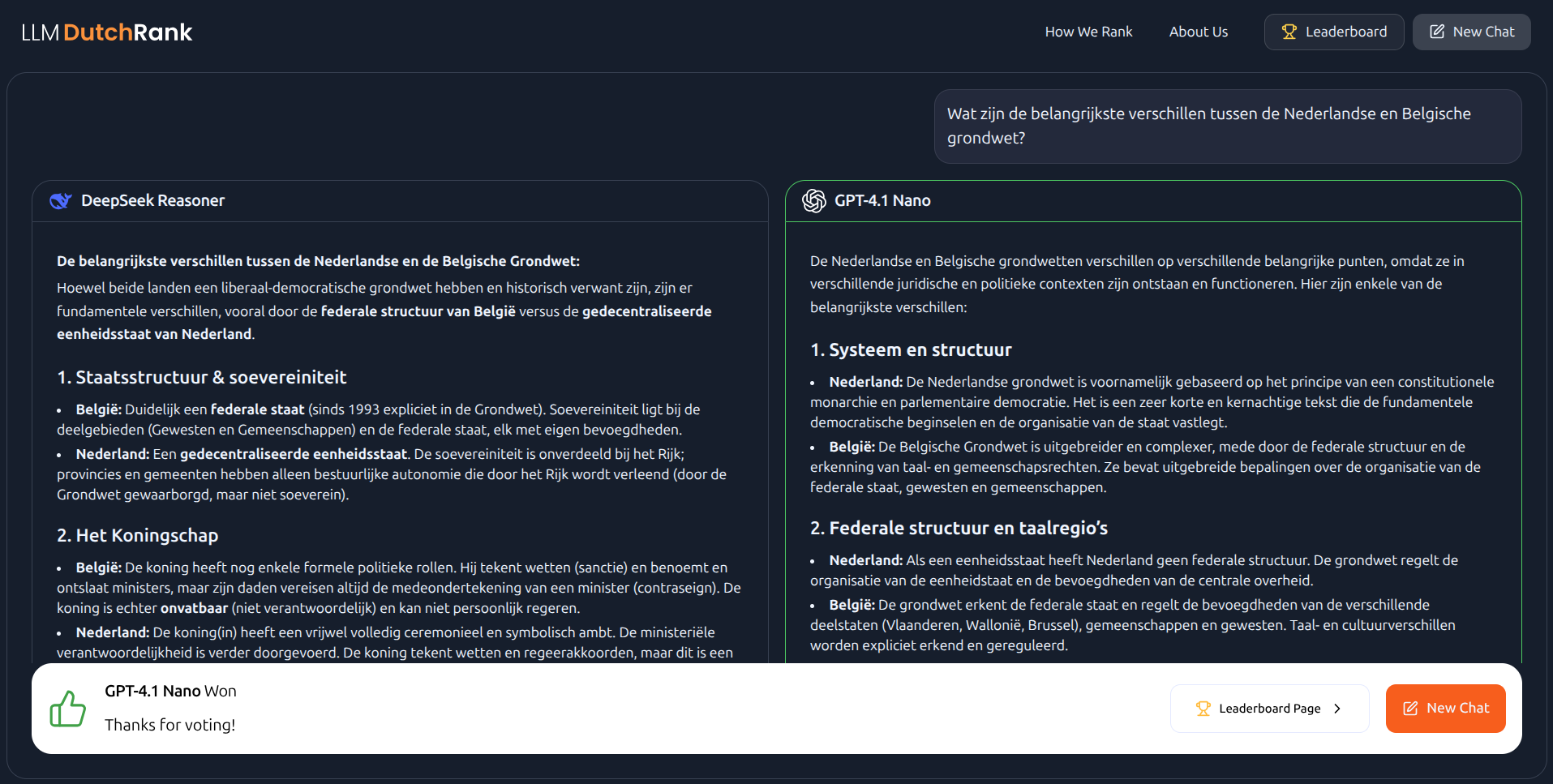
That reveal is often the moment of surprise. People who were sure they knew the best model regularly discover they voted for something else. That is the entire point of blind evaluation. In unblinded tests, the same text gets rated higher when it carries a familiar brand name. Hiding the names forces the judgment onto the writing itself.
How the rankings work
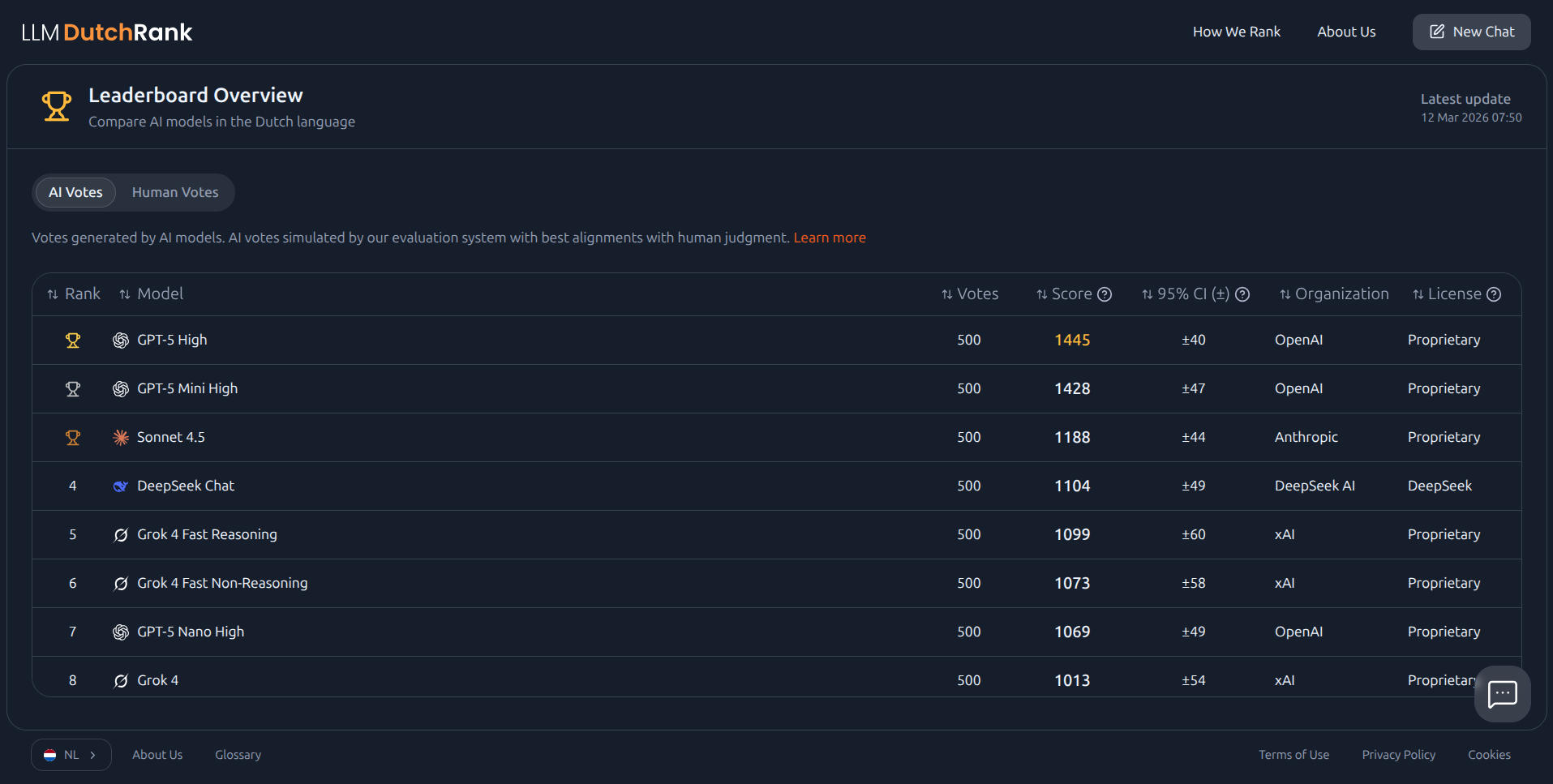
DutchRank's primary leaderboard is built from those blind human votes. The ranking math comes from established statistical methods, the same family of algorithms used in competitive chess, adapted for the messier problem of subjective language quality. Confidence intervals show how certain the rankings are. When two models are too close to call, the leaderboard says so honestly.
Alongside the human leaderboard, DutchRank publishes a secondary AI Votes leaderboard. It uses automated AI-as-judge comparisons, following the Arena-Hard methodology (ICML 2025)[1], and serves as a bootstrap signal while human votes accumulate. It's there to give early visibility, not to replace the human ranking.
Where this is going
A preference signal tells you which model Dutch speakers like better. It doesn't yet tell you why. When Model A beats Model B, the leaderboard can't say whether it was grammar, reasoning, cultural knowledge, or just a friendlier tone.
That's the work happening alongside the arena: an Automated Evaluation track that breaks the single preference signal into objective, capability-level scores. Curated Dutch datasets, one capability at a time. Which model gets Dutch grammar right. Which one reasons correctly. Which one follows instructions precisely. The goal is to combine the two pillars in one place, so the same model gets evaluated for both capability and usability against the same Dutch-native standard.
The hardest part is data, not infrastructure. The approach is to favor datasets that genuinely reflect how Dutch is read and written. That includes native Dutch datasets where they exist, new ones built where they don't, and translated material that has been reviewed and corrected by Dutch speakers before it enters the benchmark. The goal isn't purity of origin, it's quality the language actually deserves. Scoring favors reproducible methods like exact match and programmatic checkers wherever the task allows it, with LLM-as-judge reserved for the small set of datasets where the task genuinely needs it.
DutchRank is also opening to model providers. Today, the team chooses which models enter the arena. Soon, anyone who has trained or fine-tuned a model for Dutch will be able to register it, run it against the full evaluation suite, and see where it stands on the same leaderboard, with the same methodology. This matters especially for open-source models that can't attract enough users on their own to produce statistically meaningful human rankings.
The long-term goal is shared infrastructure for the Dutch AI ecosystem. Public results, transparent methodology, fair evaluation for every model.
Try it out yourself at DutchRank.