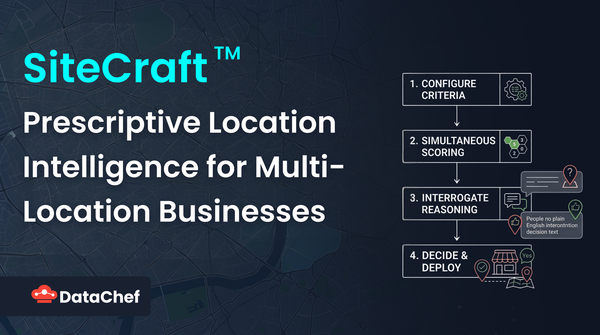
Serverless Machine Learning Inference
Why Serverless Machine Learning Inference? So now you have trained your machine learning model, and it works well; finally other people can use it. To make your model accessible to others, you need to deploy it on a server that gets the inputs and re...


Why Serverless Machine Learning Inference?
So now you have trained your machine learning model, and it works well; finally other people can use it. To make your model accessible to others, you need to deploy it on a server that gets the inputs and returns your model’s prediction, but having a server up and running all the time may not be a cost-effective option for you.
This can be the case in many scenarios. For example, your model may be for proof of concept or research purposes and doesn’t have a large request load. Another scenario would be models with intermittent request loads, so there is so much idle time, and you don’t want to pay for a server when it’s not used.
Here Serverless Inference comes to actions where you only pay for what you have used and not the idle times. In our post on Serverless Architectures - Pause, Think, and then Redesign, we talked about the advantages of serverless architecture in general. Here we will focus on its use cases in machine learning inference.
To get a sense of how cost-effective serverless inference can be, here we compared a 10000 request per day workload endpoint using both serverless AWS Lambda and an ordinary SageMaker Endpoint. For both approaches, we have used a Random Forest Regressor model from Skearn.
| Type of Architecture | No of Requests per day | Latency of Each Request | Amount of Memory Allocated | Total Cost Estimate/ Month (USD) |
| Serverless (Lambda) | 10000 | Warm start ~ 200 ms / Cold Start ~ 3s | 512 MB | 0.57 |
| SageMaker Endpoint (ml.t2.medium instance) | 10000 | 190 ms | - | 40.32 |
This post will review and compare the available options for building a machine learning serverless inference endpoint within AWS services. You can find the best one according to your specific use case.
What are the real-time API options?
For most use cases, you need to deploy your model as a REST-API so others can send a POST request and get a response with low latency (usually not more than a second). This part will cover what options are available for creating such an API.
AWS Lambda
- How does this service work?
Lambda is an event-driven, serverless computing platform that runs your provided script in response to a trigger. There are many options for triggering a Lambda function. For machine learning inference, it’s usually a REST-API call that comes from API-Gateway to Lambda. Our Lambda function gets the input data and returns the predictions using our trained model.
Note that there are two ways to deploy a Lambda function. One option is to use a .zip file that can not be over 50MB (its unzipped size shouldn’t be over 250 MB) and contains all your inference code and model. The other option is through a Docker image from ECR, which can be up to 10GB in size, so you have more space for your model artifacts and dependencies.
- How is the pricing?
AWS charges you for a combination of the number of requests you have sent to the lambda and the memory and time each request has consumed. You can allocate any amount of memory between 128 MB and 10,240 MB (with 1 MB steps) to your function.
| CPU Architecture | Duration | Requests |
| x86 | $0.0000166667 for every GB-second | $0.20 per 1M requests |
| ARM | $0.0000133334 for every GB-second | $0.20 per 1M requests |
For example with a 1M requests load that each of the requests took about 200ms, with 1024MB of memory allocated, the price for an ARM based Lambda would be:
1M * 0.2 + 1M * 200ms * 0.001 * 0.0000133334 = 0.20 USD (monthly request charges) + 2.67 USD (monthly compute charges) = 2.87 USD
- For which scenarios is this service ideal?
Lambda is ideal for real-time APIs with unpredictable request loads since it can scale fast. Also, its pricing is suitable for a type of request that takes a short time to be processed. So as long as you are fine with its limitations (10GB Memory cap and CPU numbers), Lambda can be a good option. However, one of its drawbacks for machine learning inference is that you have to develop a CI/CD pipeline to update the Lambda function whenever you update/retrain the model.
Amazon SageMaker Serverless Inference
- How does this service work?
Introduced in re:invent 2021, SageMaker serverless inference is a new option for deploying your model in SageMaker. Unlike traditional deployment options that use specific EC2 instances, SageMaker Inference uses Lambda to serve your model. Hence, it has both the advantages and limitations of Lambda, plus the better integrity with SageMaker environment that offers you a better CI/CD workflow through SageMaker Projects and SageMaker Pipelines.
- How is the pricing?
SageMaker uses a bit different pricing than Lambda. It charges you based on a combination of milliseconds that it takes to process and the amount of data you send/receive. See more on the SageMaker Pricing page.
- For which scenarios is this service ideal?
If your team uses SageMaker services, this new option is more straightforward to deploy than Lambda. Note that SageMaker inference has a lower memory cap (6144 MB instead of 10GB), so if 6144 MB is not enough for your model, you should probably consider Lambda or a regular SageMaker Endpoint.
What are the Batch Transform options?
Sometimes you don’t need a real-time API, and requests can be responded to with longer latency, or you can collect them and make the inference periodically. It’s called batch transform, and In this part, we will cover what options are available for that.
AWS Fargate
- How does this service work?
AWS Fargate is a serverless container orchestration service that helps you deploy and scale your containerized application, and it’s compatible with Amazon ECS service. If you want to use Fargate for a real-time inference API, it would be similar to deploying a dockerized web application on EC2 but in a serverless way. But as we will see in the pricing part, AWS Fargate is more optimized for batch processing jobs. These jobs are either started periodically or by a trigger of an event and are finished after a while. AWS Fargate is commonly used for tasks longer than 15 minutes, which Lambda does not support.
- How is the pricing?
Fargate charges you on a combination of the virtual CPUs (vCPUs) and memory you have used. Since it’s designed for large tasks, it has a 1 minute minimum for billing. For a larger vCPU, you have larger memory options, up to 30 GB Memory for 4 vCPUs.
- For which scenarios is this service ideal?
In summary, Fargate is not a good choice for a real-time API. Suppose you have a batch job and also want good customization for your environment, and you don’t want to use SageMaker Batch Transform. In that case, Fargate can be a good option.
Amazon SageMaker Batch Transform
- How does this service work?
SageMaker Batch Transform is a part of SageMaker inference services that helps you with the prediction of large datasets that don’t need to be real-time. It’s not technically “serverless” as it works the same way as SageMaker Endpoint, but instead of opening an API to outside, it downloads the input data from S3, gets the prediction from the loaded model for that data using a POST request to localhost, and saves the result in S3. This can scale well with your use case as you can increase the number of instances and send POST requests for a batch of inputs instead of one at a time.
- How is the pricing?
Using SageMaker Batch Transform, you are charged based on how long your job takes to finish, and on the instance type you chose. See more on the SageMaker Pricing page.
- For which scenarios is this service ideal?
SageMaker Batch Transform is an ideal choice for jobs that don’t require to be done in a real-time manner, such as personalized recommendations. Since it is well integrated into the SageMaker environment, you can easily use it as a part of your SageMaker pipeline.
Conclusion
Here, we discussed four different AWS Services for machine learning serverless inference. In summary, if you have an unpredictable request loads pattern and your model doesn’t need GPU or huge memory to run, you should consider Lambda or Sagemaker Serverless Inference. If you don’t need a real-time endpoint, you can use SageMaker Batch Transform or build your version using Fargate.
The following table summarizes what we have covered in this post:
| AWS Service | Suitable Type | Cost Estimate (USD) | Development Effort | Latency for RealTime API |
| Lambda | RealTime API | 0.019 | Medium | Warm start Latency ~ 200 ms / Cold Start Latency ~ 3s |
| SageMaker Serverless Inference | RealTime API | 0.04032 | Low | Warm start Latency ~ 200 ms / Cold Start Latency ~ 3s |
| Fargate | Batch Transform | 0.0146 | High | NA |
| SageMaker Batch Transform | Batch Transform | 0.067 | Low | NA |
The cost column has been calculated for one day with 10000 requests. Each request takes 200ms to process and has a 1KB size for both input and output. The minimal CPU and memory have been selected for a Random Forest model.