What Cloud Has to Offer to Life Science: Serverless
Introduction As you delve deeper into coding and your code becomes too heavy to run on your laptop, you may need to transfer your workload to a Cloud or High-Performance Computing (HPC) server. Computational Biology and Bioinformatics as a field have...


Introduction
As you delve deeper into coding and your code becomes too heavy to run on your laptop, you may need to transfer your workload to a Cloud or High-Performance Computing (HPC) server. Computational Biology and Bioinformatics as a field have long passed this level with the everyday increasing data such as genetic sequences that call for more storage space and better computing capabilities. This challenge is classically solved by providing the researchers with Virtual Machines (powerful computers in data centers) to meet their computational needs. Although being a useful method for fairly simple tasks, it comes with a cost that is time that needs to be spent on configuration and maintenance of the VM for that workload. This needs to be done by either the researcher themselves or a technical support person, both undesirable in an academic environment. Here we explore Serverless as a new paradigm in Cloud computing for life science workloads and show its potential to help researchers in several aspects of their projects.
The Concept of Serverless
What is Serverless Serverless computing is a cloud-based model that eliminates the need for developers or users to worry about the underlying infrastructure. Unlike traditional models, in serverless computing, the responsibility for managing servers, databases, and other critical infrastructure elements is shifted to the cloud provider. Users are thus freed from the burden of setting up and managing these systems, allowing them to focus more on their core tasks.
How Serverless Works In the serverless model, applications are typically broken down into individual functions that are executed in response to events. These functions, known as Function-as-a-Service (FaaS), run in stateless compute containers that are fully managed by the cloud provider. Once an event triggers a function, the cloud provider automatically allocates the necessary resources to run it. When the function is complete, the resources are de-provisioned, thus creating an on-demand, highly efficient system.
The Applicability of Serverless in Life Science
There are two general workload types in a research project that can benefit from moving to Serverless.
- Data Pipeline
The first one is data pipelines which involve preprocessing of input data as well as running the main algorithm on it and storing the final result. Grzesik et al. Classify this pipeline into three main steps (data preparation, parallel processing, and post-processing) and emphasize that the parallel processing step can benefit from Serverless. Here is a diagram showing such workflow:
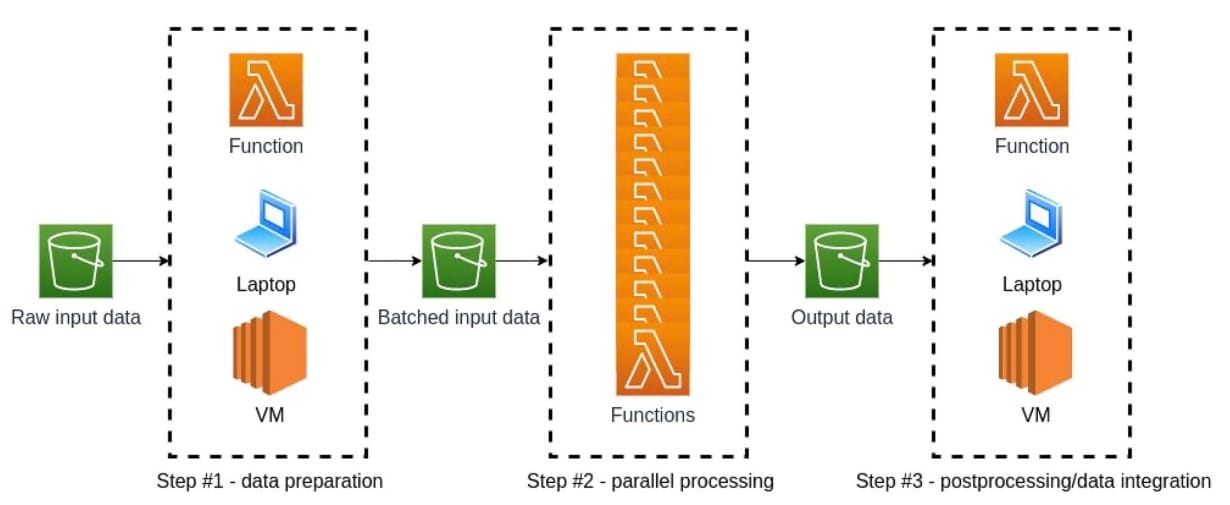
- Credit: Grzesik et al 2021
- Deployment
The second one that is less explored but has much potential is the Serverless deployment of bioinformatics tools. Traditionally, when researchers develop a computational tool or an algorithm, there are two ways of publishing it so the final users, usually biologists, can access it.
The first one is publishing the source code/tool on websites like GitHub and providing the necessary instruction on how users can set up the tool on their computers. This is not always desirable since the setup can be complicated, and biologists prefer easy-to-use interfaces like websites, so the other option would be to put your tool behind an API and deploy it on the cloud so the user can access it easily without the need to do any setup from your website. Here is where Serverless can be very useful to reduce the cost and make the deployment process much more seamless.
Consider these two scenarios to see how moving the workload to Serverless can drastically reduce the cost:
- Scenario 1 (High User Number, Low Complexity Algorithm):
Many bioinformatic algorithms are relatively low complex and can be run in a short time, and use small memory, but because of the high number of users, you need to be able to serve multiple requests at the same time, serverless with its massive scalability become very helpful. Here is the cost comparison for this scenario:
Type | Requests / Month | Average Computation Time on 1 vCPU (ms) | RAM | Cost ($) |
|---|---|---|---|---|
VM (EC2 t4g.small) | 10000 | One Medium Instance Needed | 2GB* | 12.096 |
Serverless (AWS Lambda) | 10000 | 1000 ms | 1GB | 0.168 |
In the case of a VM, we need more RAM since all the traffic needs to be served from one instance, while in serverless, in case of multiple concurrent requests, AWS automatically fires up new instances to meet with the request load.
- Scenario 2 (Low User Number, High Complexity Algorithm):
Another common pattern in bioinformatics tools is relatively complex algorithms that take more time and memory to run but have few users. You still need to have a dedicated powerful instance up and running all the time which will cost you so much, but with serverless, you only pay for the time that the algorithm was running, so the cost will drop drastically. Here is an example:
| Type | Requests / Month | Average Computation Time on 1 vCPU (ms) | RAM | Cost ($) |
| VM (EC2 t4g.large) | 1000 | One Large Instance Needed | 8GB | 48.384 |
| Serverless (AWS Lambda) | 1000 | 60,000 ms | 8GB | 8.0002 |
Note that workloads with both high user numbers and also high computation needs may not be suitable for typical serverless architectures and other options such as Kubernetes services like what LuxProvide offers.
AWS Free Tier Covers up to 400,000 GB-second of computation and 1M request/month for AWS Lambda, so basically, both of these two scenarios will be technically free forever!
Hurdles to Serverless Adoption in Life Sciences
Despite its high potential to make bioinformatics workload cheaper and more efficient, its adoption has been slow in the academic world due to multiple reasons
Potential financial problem of the academic world with Cloud The pay-as-you-go pricing model of Serverless is very appealing to an agile company that wants to iterate fast between ideas and prototype them, but academia is definitely not famous for agility and risk-taking, so sometimes they actually prefer a high constant bill for a VM instead of a variable lower cost for Serverless.
Cloud learning curve Despite the ease of use for Serverless compared to a VM, it’s still a new technology that you need to spend time learning. Especially if it’s your first time using a cloud provider like AWS, it can be haunting to find your way through the thousands of services on their website!
Data security concerns Despite the rigorous data protection protocols enforced by public cloud providers, there are certain researchers working with highly sensitive information who remain hesitant to transfer their data to the public cloud. For example, research on patient data that can be compromised and used against them by insurance companies needs to be handled very carefully. For these use cases, some special cloud/HPC providers like LuxProvide might be a better option that ensures maximum possible security/privacy.
Conclusion
In this post, we covered various reasons why Serverless is a good choice for bioinformatics workload in terms of both cost and ease of deployment. We also delved into why the implementation of Serverless technology has been lackluster in this domain, despite its numerous advantages. We believe by leveraging serverless computing; the life science community can accelerate research, drive innovation, and ultimately contribute to important breakthroughs in our understanding of biological processes and diseases.
References :
- Serverless computing in omics data analysis and integration
- Leveraging Serverless Computing to Improve Performance for Sequence Comparison
- Challenges and Opportunities of Amazon Serverless Lambda Services in Bioinformatics
What is serverless computing?Serverless computing is a cloud-based model that eliminates the need for developers or users to worry about the underlying infrastructure. It shifts the responsibility of managing servers, databases, and other critical infrastructure elements to the cloud provider.How does serverless computing work?In serverless computing, applications are broken down into individual functions that are executed in response to events. These functions, known as Function-as-a-Service (FaaS), run in stateless compute containers managed by the cloud provider. Resources are allocated automatically when a function is triggered, and de-provisioned once it completes, creating an on-demand and efficient system.How can serverless benefit data pipelines in life science research?Serverless can benefit data pipelines by handling data preprocessing, parallel processing, and post-processing steps. With serverless, the parallel processing step can be efficiently managed, reducing the need for manual configuration and maintenance.Why is serverless deployment beneficial for bioinformatics tools?Serverless deployment simplifies the process of publishing computational tools or algorithms for biologists. Instead of setting up tools on individual computers, serverless deployment allows researchers to put their tools behind an API on the cloud. This reduces costs, provides easy access, and streamlines the deployment process for end users.